Unsafe Rust
Unsafe Rust(Unsafe Rust)是Rust编程语言中的一种特性,它允许程序员绕过Rust的内存安全性,执行一些可能不安全的操作,它的存在主要有以下两个重要意义:
-
灵活性和控制力:Rust的设计目标之一是提供内存安全性和线程安全性,以避免常见的程序错误,如空指针引用和数据竞争。然而,有些情况下,程序员需要执行一些底层、不安全的操作,例如直接操作内存、调用未经验证的外部函数或与底层硬件进行交互。不安全Rust允许程序员在这些情况下绕过编译器的检查,以完成特定任务,这提供了更大的灵活性和控制力。
-
与底层硬件和外部代码的互操作性:计算机硬件和操作系统通常不提供与Rust的内存安全性保证完全一致的保障。为了实现低级系统编程、调用C语言函数、编写操作系统内核或执行其他与硬件或外部库交互的任务,程序员可能需要使用不安全Rust。这种情况下,不安全Rust允许将Rust代码与不受Rust安全性检查的外部代码集成在一起,从而实现互操作性。
Unsafe的超能力
可以通过 unsafe 关键字来切换到 Unsafe Rust,然后开始一个包含不安全代码的新块。在 Unsafe Rust中,可以执行五个在安全的Rust中无法执行的操作:
-
解引用裸指针
-
调用 unsafe 的函数或方法
-
访问或修改可变的静态变量
-
实现unsafe 的trait
-
访问
union的字段
unsafe 关键字
unsafe 关键字并不会关闭 Rust 的借用检查器(borrow checker)或禁用其他的安全性检查。使用 unsafe 关键字只是可以使用上面的五个超能力。
unsafe 关键字并不是表示代码一定是危险的,而是表示这部分代码可能包含潜在的风险,应仔细考虑何时使用 unsafe 关键字,并尽量将不安全操作限制在最小的范围内,以降低潜在风险。
解引用裸指针
裸指针(raw pointers)是指在Rust借用系统的严格控制之外的指针。这些指针是原始的,直接指向内存地址,不提供安全性保证,因此可能引发"悬垂引用"(dangling references)问题。在Rust中,存在两种类型的裸指针:
-
*const T:这是一个不可变的裸指针,只能读不能修改。不可变裸指针与C/C++中的const指针类似。 -
*mut T:这是一个可变的裸指针,可读取数据并且修改。
与引用和智能指针不同,原始指针具有以下特点:
-
可以忽略借用规则,允许同时存在不可变指针和可变指针,或多个可变指针指向同一位置。
-
不保证指向有效内存。
-
允许为空指针。
-
不实现任何自动清理操作。
fn main() {
let mut num = 5;
let r1 = &num as *const i32;
let r2 = &mut num as *mut i32;
}
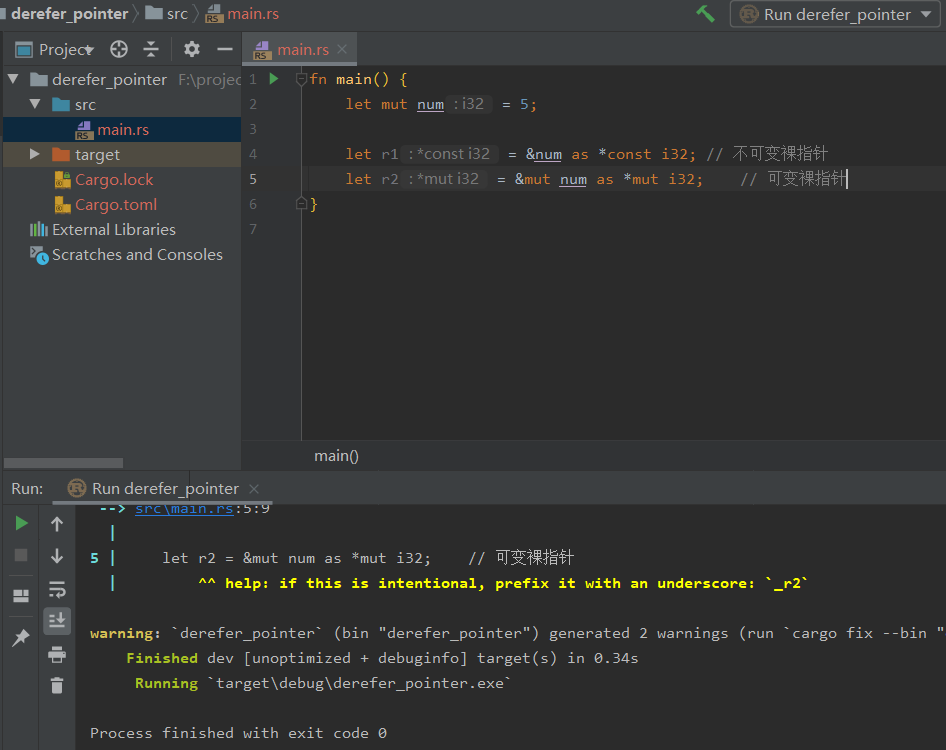 根据上面代码可知:裸指针可以在安全代码中创建。
根据上面代码可知:裸指针可以在安全代码中创建。
下面创建一个不能确定其有效性的裸指针。尝试使用任意内存是未定义行为:该地址可能包含数据,也可能不包含数据,编译器可能会优化代码以避免内存访问,或者程序可能会因分段错误而出错。
let address = 0x012345usize;
let r = address as *const i32;
// 未知代码
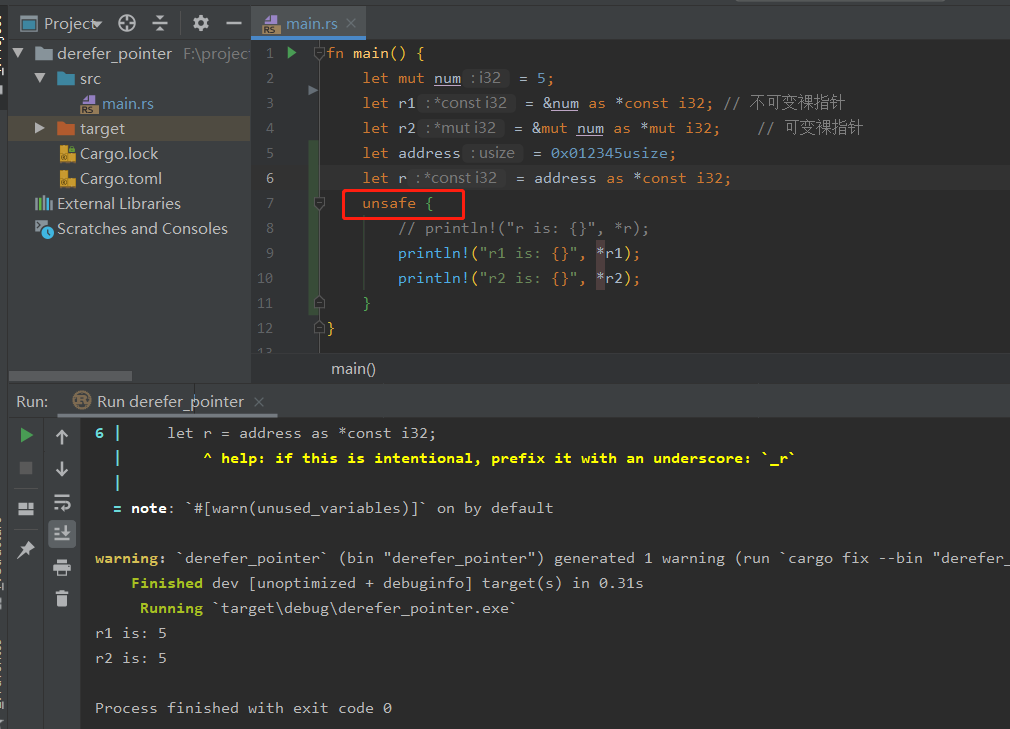
在使用裸指针指向的值时,可能会出现问题,故此时需要写在 unsafe 块中。
调用 Unsafe 函数或方法
unsafe 函数和方法相较于普通函数和方法,其在 fn 的之前有一个额外的 unsafe 关键字。
fn main() {
unsafe {
dangerous();
}
}
unsafe fn dangerous() {
println!("dangerous");
}
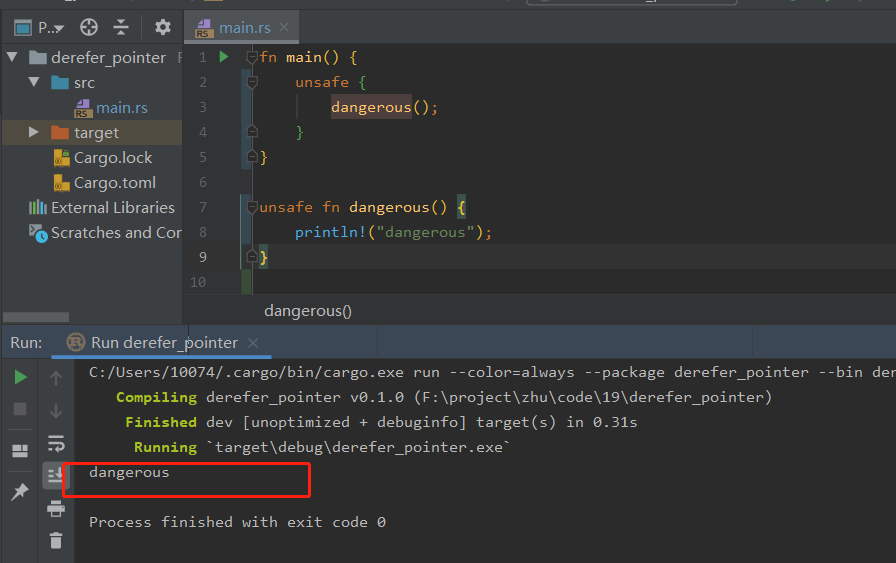
与使用裸指针类似,调用unsafe函数时,需要将其放在unsafe块中。
创建Unsafe代码的安全抽象
为了避免将一个包含不安全代码的函数标记为不安全,将不安全代码封装在一个安全函数内是一种常见的抽象方法。下面以标准库中的 split_at_mut 函数为例,此函数包含 unsafe 代码。
split_at_mut:将一个可变切片分成两部分,分割点在索引位置。第一个部分将包含所有从[0, mid)范围内的索引(不包括索引mid本身),第二个部分将包含所有从[mid, len)范围内的索引(不包括索引len本身)。
pub const fn split_at_mut(&mut self, mid: usize) -> (&mut [T], &mut [T]) {
assert!(mid <= self.len());
// SAFETY: `[ptr; mid]` and `[mid; len]` are inside `self`, which
// fulfills the requirements of `from_raw_parts_mut`.
unsafe { self.split_at_mut_unchecked(mid) }
}
运行测试代码:
fn main() {
let mut v = vec![1, 2, 3, 4, 5, 6];
let r = &mut v[..];
let (a, b) = r.split_at_mut(3);
println!("{:?}", a);
println!("{:?}", b);
}
// [1, 2, 3]
// [4, 5, 6]
下面仿照 split_at_mut 方法,在安全的 rust 中实现一个类似的函数。
pub const fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
assert!(mid <= len);
(&mut values[..mid], &mut values[mid..])
}
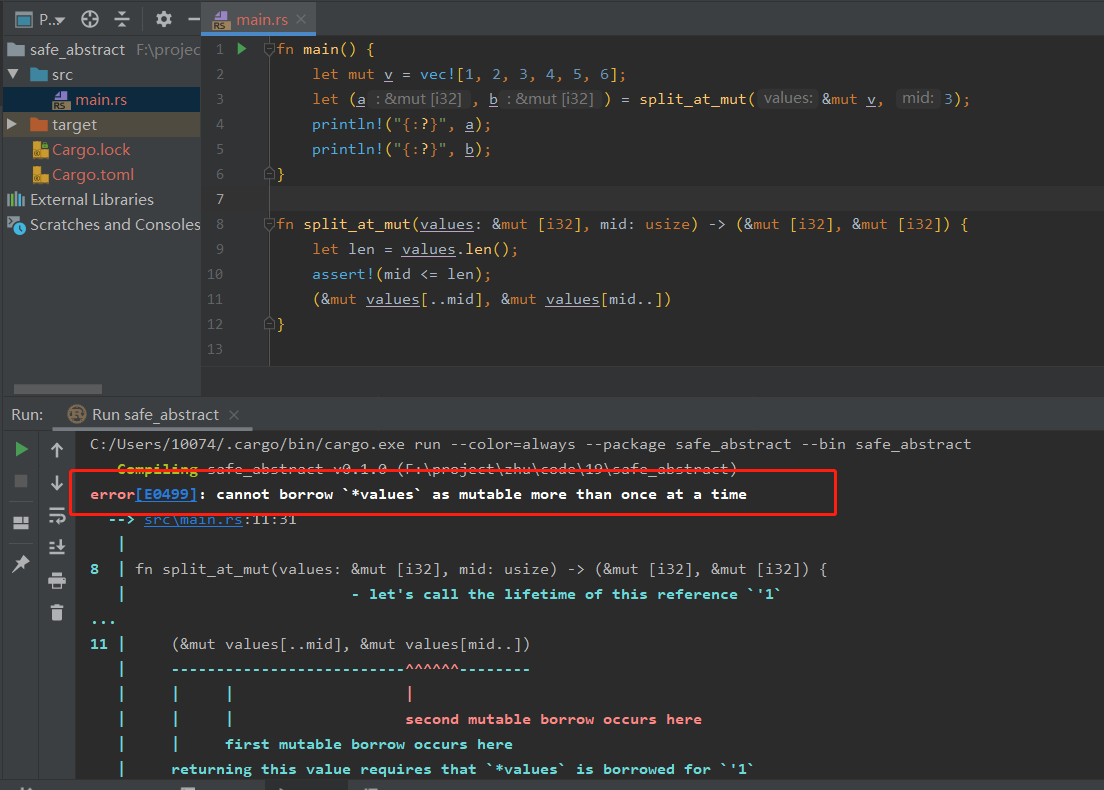
Rust 借用检查器只知道我们两次从同一个切片进行借用,并不知道两个切片并不重叠。此时就是使用 Unsafe Rust的时候了。修改代码:
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
let ptr = values.as_mut_ptr();
assert!(mid <= len);
unsafe {
(
slice::from_raw_parts_mut(ptr, mid),
slice::from_raw_parts_mut(ptr.add(mid), len - mid),
)
}
}
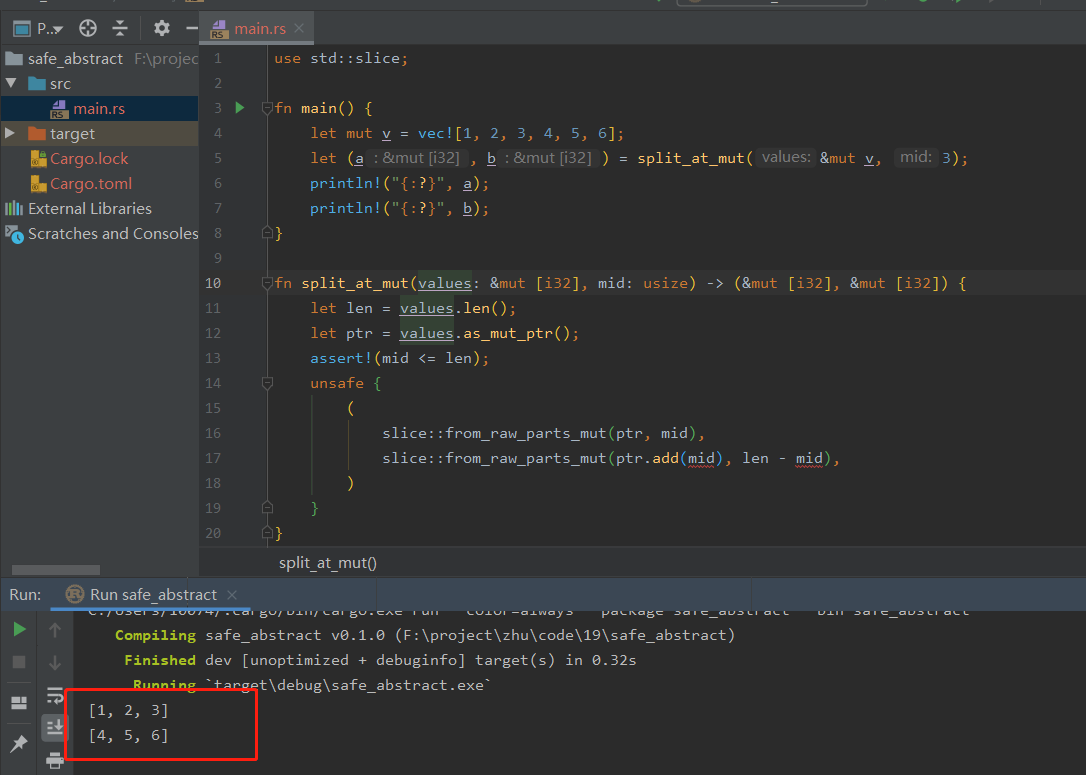
函数返回一个指向切片缓冲区的unsafe可变指针。此指针的操作通常需要放在 unsafe 块内,允许对切片中的元素进行直接的读写操作。
函数用于从一个原始的可变指针和一个长度创建一个可变切片(&mut [T]),同时此函数是unsafe的,因为它依赖于调用者提供有效的指针和长度,并且不进行边界检查。
下面使用 slice::from_raw_parts_mut 函数从一个未知的内存位置,并创建一个包含10,000个项目的切片。
use std::slice;
fn main() {
let address = 0x01234usize;
let r = address as *mut i32;
let values: &[i32] = unsafe{
slice::from_raw_parts_mut(r, 10000)
};
// for i in values {
// println!("{}", i);
// }
// println!("slice len is {}", values.len());
}
当试图访问 value 内容时,这个地址可能指向任何内容,包括无效的、未初始化的、或者与 i32 类型不匹配的数据。
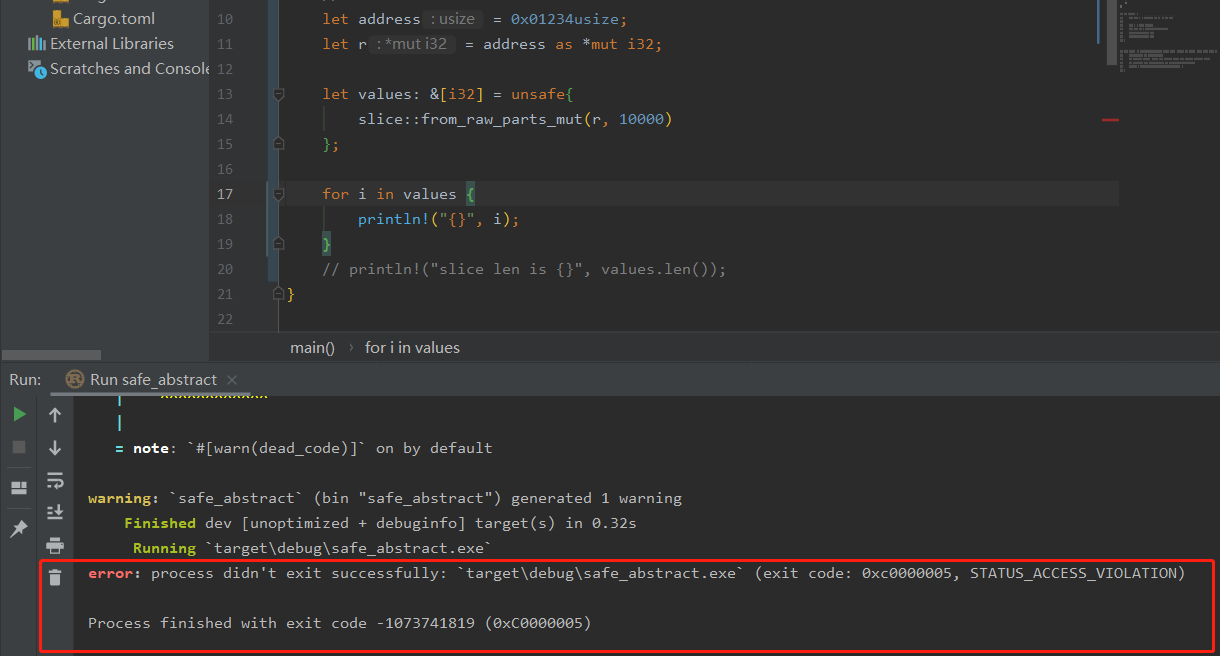
此错误是一个访问违例(Access Violation)错误,通常表明你的程序在试图访问无效的内存位置时崩溃了。但若只打印切片的长度,则此代码是安全的,因为这不涉及访问切片的内容。
使用外部函数与外部代码交互
extern 关键字在 Rust 中用于声明外部函数和接口,主要用于与其他编程语言进行交互。它简化了创建和使用外部函数接口(Foreign Function Interface,FFI)的过程。通过 FFI,Rust 可以调用其他语言编写的函数,并允许其他语言调用 Rust 编写的函数。它允许 Rust 与现有的 C、C++、Python 等库和代码进行集成。
extern "C"{
fn abs(input: i32) -> i32;
}
fn main() {
unsafe {
println!("Absolute value of -3 according to C: {}", abs(-3));
}
}
// Absolute value of -3 according to C: 3
在 Rust 中,通常使用 extern "C" 来声明与 C 语言兼容的外部函数接口。abs 函数来自 C 标准库(C Standard Library)。 Rust 内置了对 C 标准库的支持。下面是开发rust共享库的方式:
#[no_mangle] pub extern "C" fn call_from_c() { println!("Just called a Rust function from C!"); } #[no_mangle]注解,告诉Rust编译器不要对该函数的名称进行重命名。
访问或修改可变静态变量
rust支持静态变量(全局变量),但是在所有权规则下可能会引发问题,即:如果两个线程访问同一个可变的全局变量,这可能会导致数据竞争。全局静态变量的声明与使用如下:
static HELLO_WORLD: &str = "Hello, world!";
//等价于 static HELLO_WORLD: &'static str = "Hello, world!";
fn main() {
println!("name is: {}", HELLO_WORLD);
}
静态变量的名称采用 SCREAMING_SNAKE_CASE。静态变量只能存储生命周期为'static 的引用,Rust编译器可以推断生命周期。可变静态变量:
static mut COUNTER: u32 = 0;
fn add_to_count(inc: u32) {
unsafe {
COUNTER += inc;
}
}
fn main() {
add_to_count(3);
unsafe {
println!("COUNTER: {}", COUNTER);
}
}
// COUNTER: 3
任何读写静态变量的代码必须位于unsafe块内。在多线程下可变静态变量很难保证不出现数据竞争,需搭配线程安全智能指针来使用。
常量和静态变量的区别:
-
内存地址固定性:
-
常量:常量在编译时被内联到代码中,没有固定的内存地址。
-
静态变量:静态变量在内存中具有固定的地址,因此可以在不同的地方引用相同的内存位置。
-
-
可变性:
-
常量:常量始终是不可变的,不能被修改。
-
静态变量:静态变量可以是可变的,但访问和修改可变的静态变量被认为是不安全的操作,需要特殊的注意和安全保障。
-
实现Unsafe Trait
当一个trait的至少一个方法具有编译器无法验证的不变量(invariant)时,该trait被视为unsafe。
unsafe trait Foo {
// methods go here
}
unsafe impl Foo for i32 {
// method implementations go here
}
fn main() {}
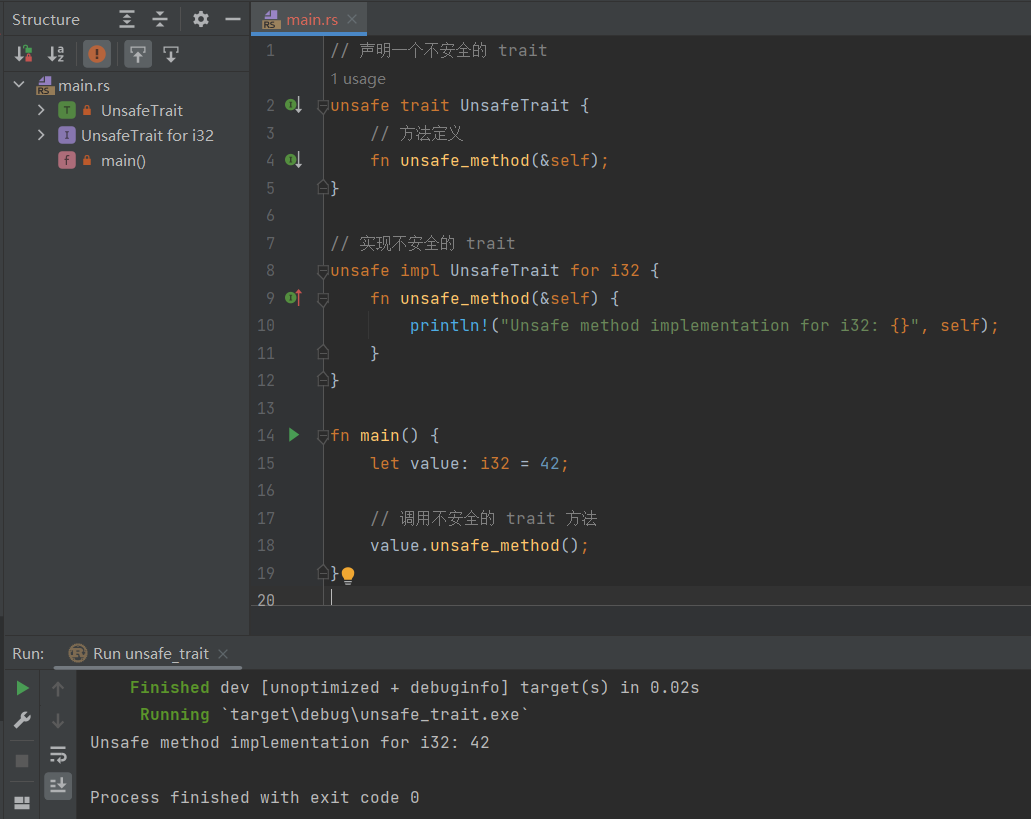
使用unsafe impl 表示我们承诺会维护编译器无法验证的一些安全性规则。例如,如果我们希望将一个类型标记为 Send 或Sync,但这个类型包含了编译器无法验证的操作(比如使用了原始指针等),那么我们必须使用 unsafe 来表明我们会手动确保这些操作的安全性,因为 Rust 无法自动验证它们。
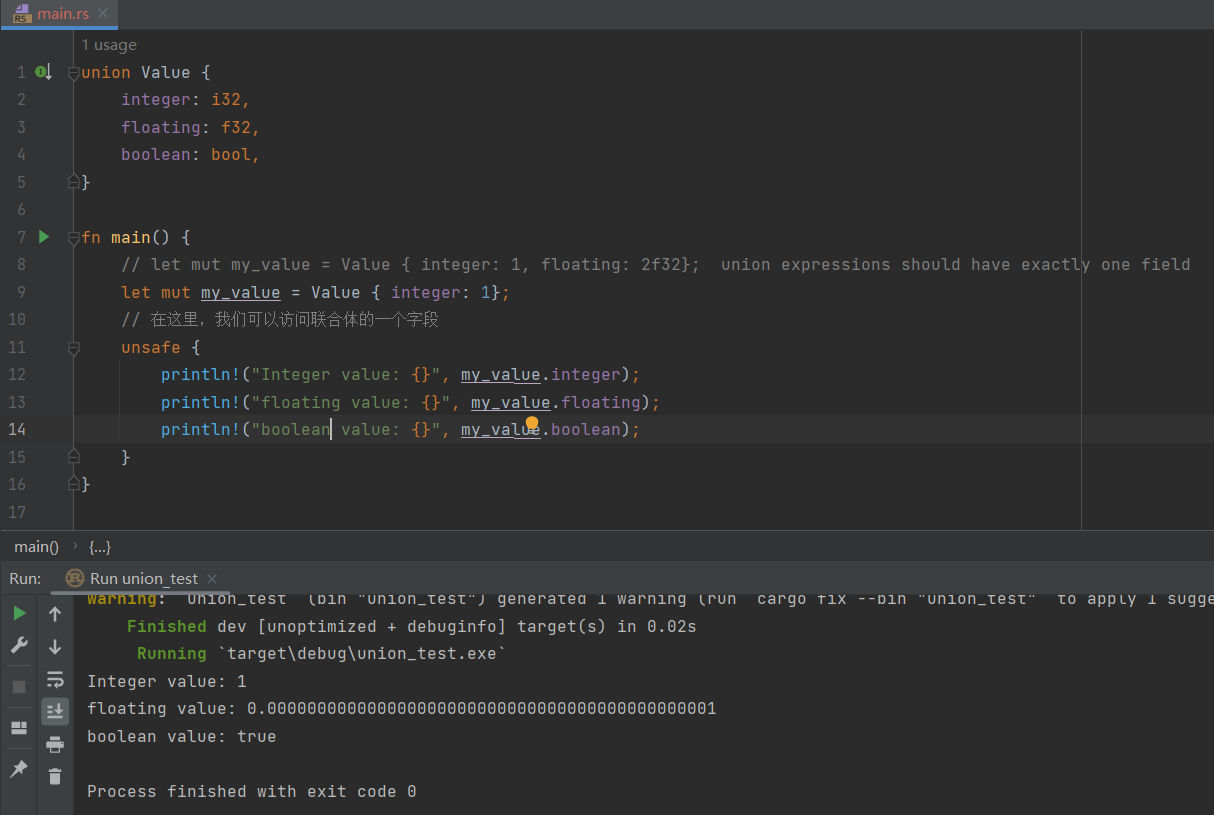
访问 union 的字段
只有使用 unsafe 才能访问 union 的字段,因为 Rust 无法保证当前存储在union 实例中的数据的类型。union类似于结构体,但在特定实例中声明一个字段。.
union Value {
integer: i32,
floating: f32,
boolean: bool,
}
fn main() {
// let mut my_value = Value { integer: 1, floating: 2f32}; union expressions should have exactly one field
let mut my_value = Value { integer: 1};
// 在这里,我们可以访问联合体的一个字段
unsafe {
println!("Integer value: {}", my_value.integer);
// println!("floating value: {}", my_value.floating);
// println!("boolean value: {}", my_value.boolean);
}
}
用法上其实是可以访问没有赋值的字段的:
高级特征
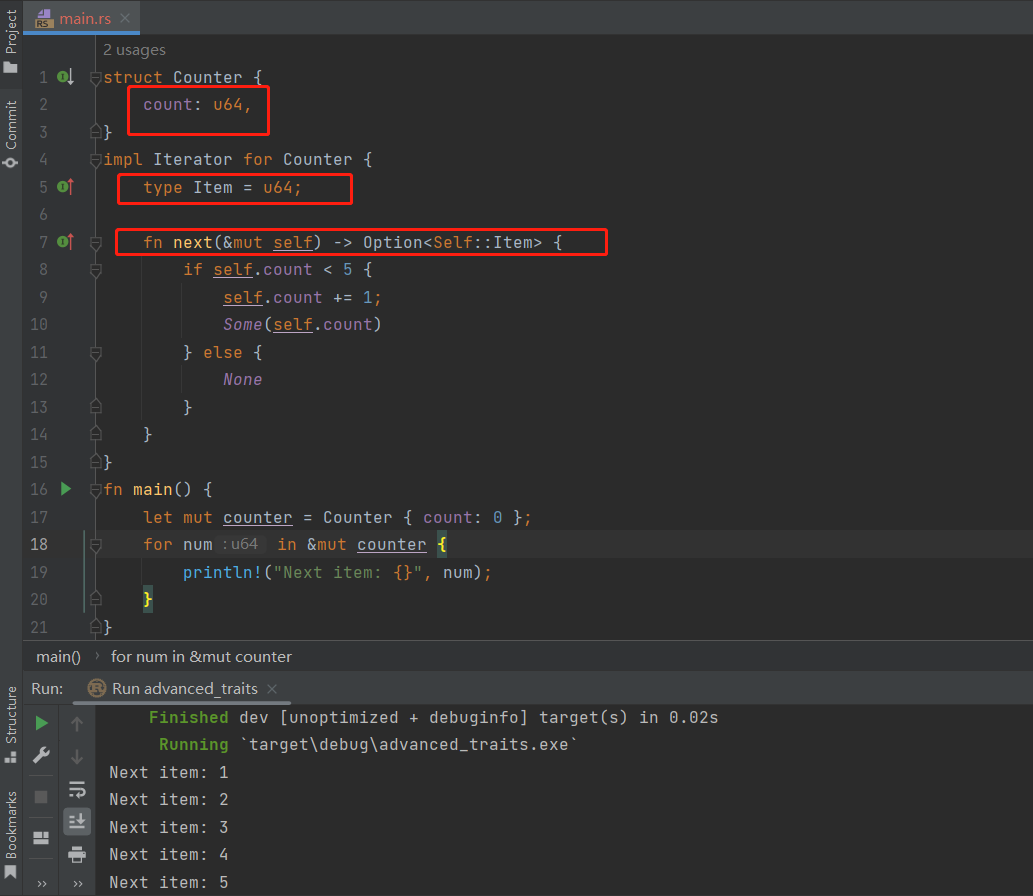
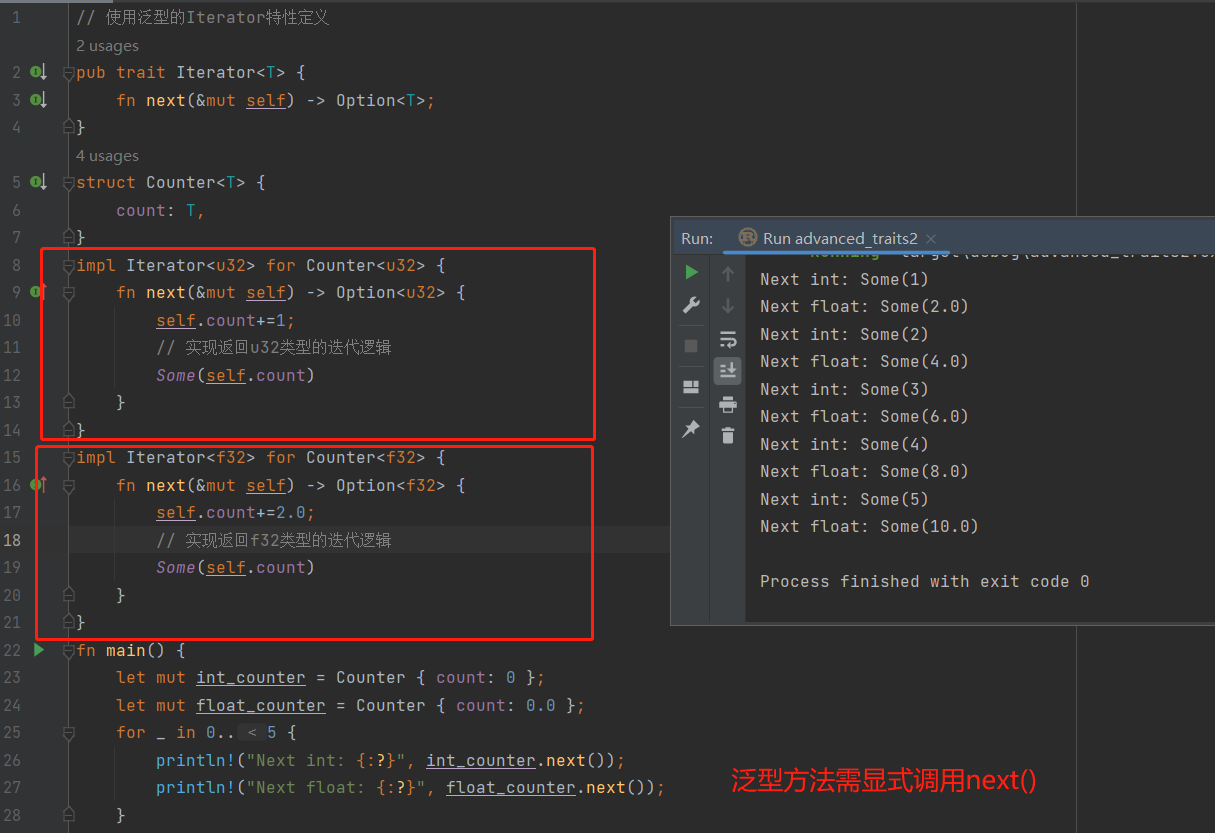
关联类型在 trait 定义中指定占位符类型
关联类型(associated types)是一个将类型占位符与 trait 相关联的方式,这样 trait 的方法签名中就可以使用这些占位符类型。trait 的实现者将为特定的实现指定具体类型,以替代占位类型。这样一来,我们可以定义一个特性,它使用某些类型,而无需在实现该特性之前确切知道这些类型是什么。
标准库中的 Iterator trait:
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}
类型 Item 是一个占位符,而next方法的定义显示它将返回类型为 Option Self::Item 的值。实现 Iterator 特性的类型将为 Item 指定具体类型,并且next 方法将返回一个包含该具体类型值的 Option。实现了 Iterator 特性的类型能够通过 for 循环来进行自动迭代(next方法)。
关联类型看起来与同泛型相似,泛型允许我们定义一个函数而不指定它可以处理的类型。但实际上二者是存在差别的:使用泛型时我们必须在每个实现中标注类型,而使用关联类型时不需要标注类型,因为不能多次在类型上实现一个特性。
默认泛型类型参数和运算符重载
当使用泛型类型参数时,可以为泛型类型指定默认的具体类型,指定默认类型的语法是在声明泛型类型时使用 <PlaceholderType=ConcreteType>,此技术一般用于运算符重载。
Rust 不允许创建自定义运算符或重载任意运算符,不过 std::ops 中所列出的运算符和相应的 trait 可以通过实现运算符相关 trait 来重载。
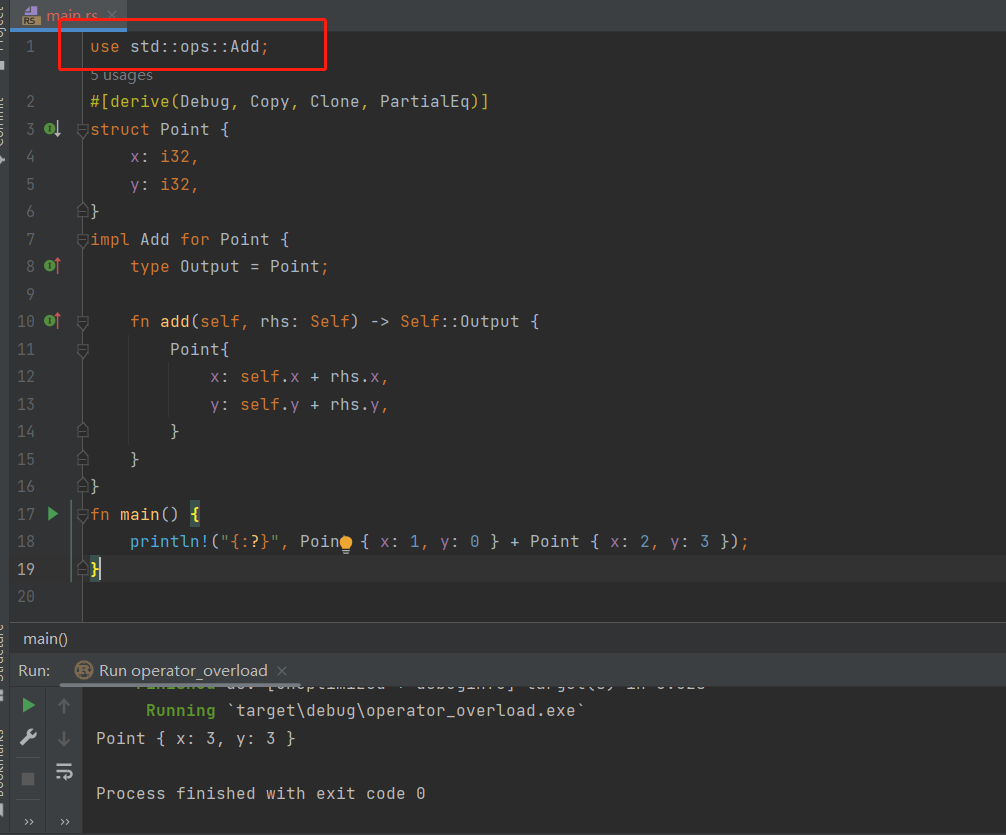
Add trait 的定义:
trait Add<RHS=Self> {
type Output;
fn add(self, rhs: RHS) -> Self::Output;
}
根据 默认类型参数 RHS=Self,可知,add 方法默认会接受一个相同类型的值。下面修改 默认类型参数 为特定类型:

调用相同名称的方法
Rust 既不能避免一个 trait 与另一个 trait 拥有相同名称的方法,也不能阻止为同一类型同时实现这两个 trait。下面两个 trait 都有一个fly方法,Human 本身也实现了一个名为fly的方法。
struct Human;
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("UP!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
person.fly();
}
// *waving arms furiously*
调用fly方法会执行 Human 类型上的fly方法,若 Human 类型上没有fly方法,会产生运行时错误:
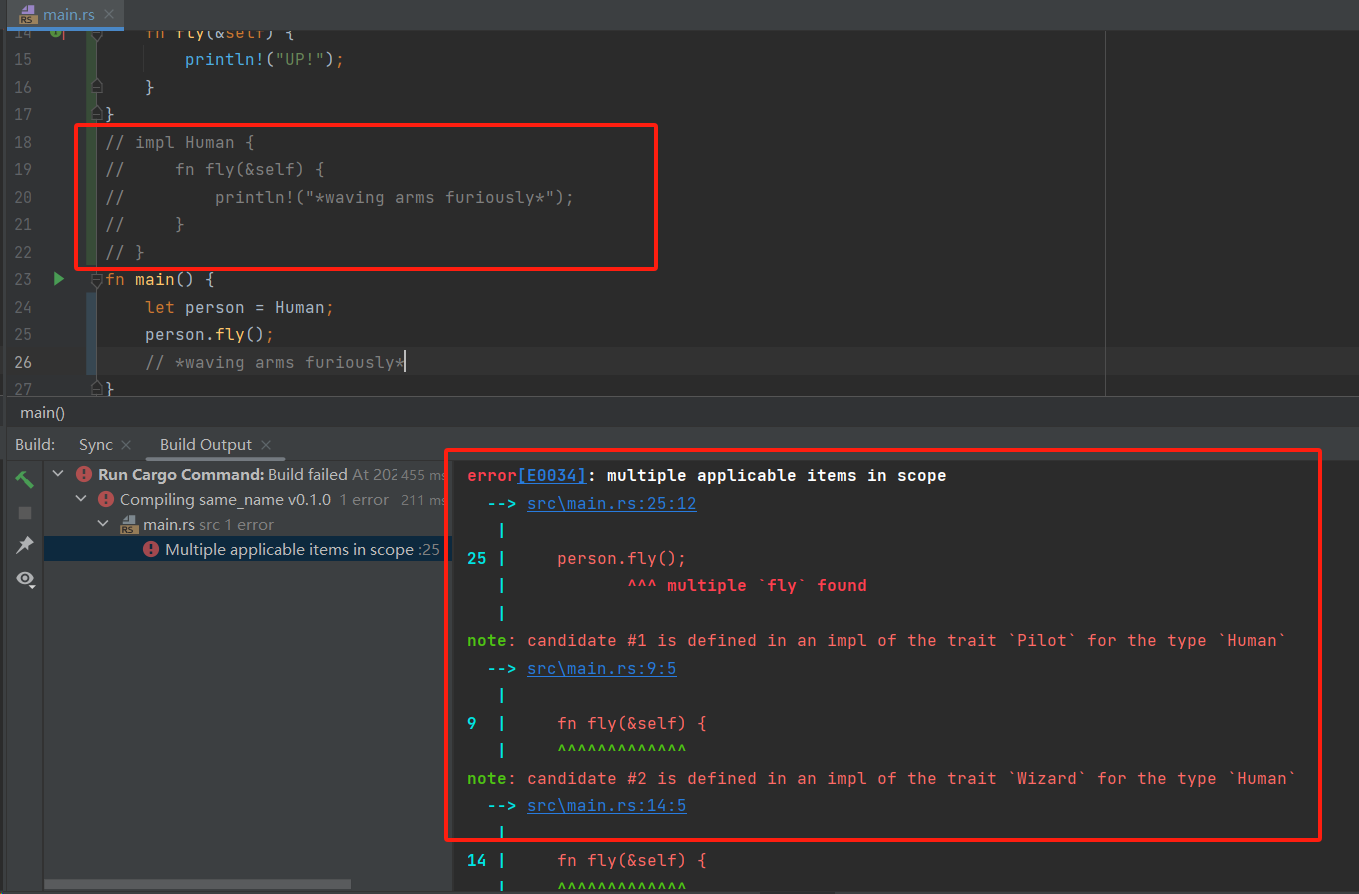
调用 trait 方法的语法如下,
fn main() {
let person = Human;
Pilot::fly(&person);
Wizard::fly(&person);
Human::fly(&person);
person.fly();
}
// This is your captain speaking.
// UP!
// *waving arms furiously*
// *waving arms furiously*
当存在多个类型或trait定义了具有相同函数名称的 关联函数 或 静态函数 时,需使用完全限定语法。
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Dog::baby_name());
// println!("A baby dog is called a {}", Animal::baby_name());
// cannot call associated function on trait without specifying the corresponding `impl` type
println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
}
// A baby dog is called a Spot
// A baby dog is called a puppy
关联函数无法通过 trait::function(&person) 来调用,因没有 self 参数无法通过编译。需通过
完全限定语法。
<Type as Trait>::function(receiver_if_method, next_arg, ...);
父 trait 使用另一特征的函数
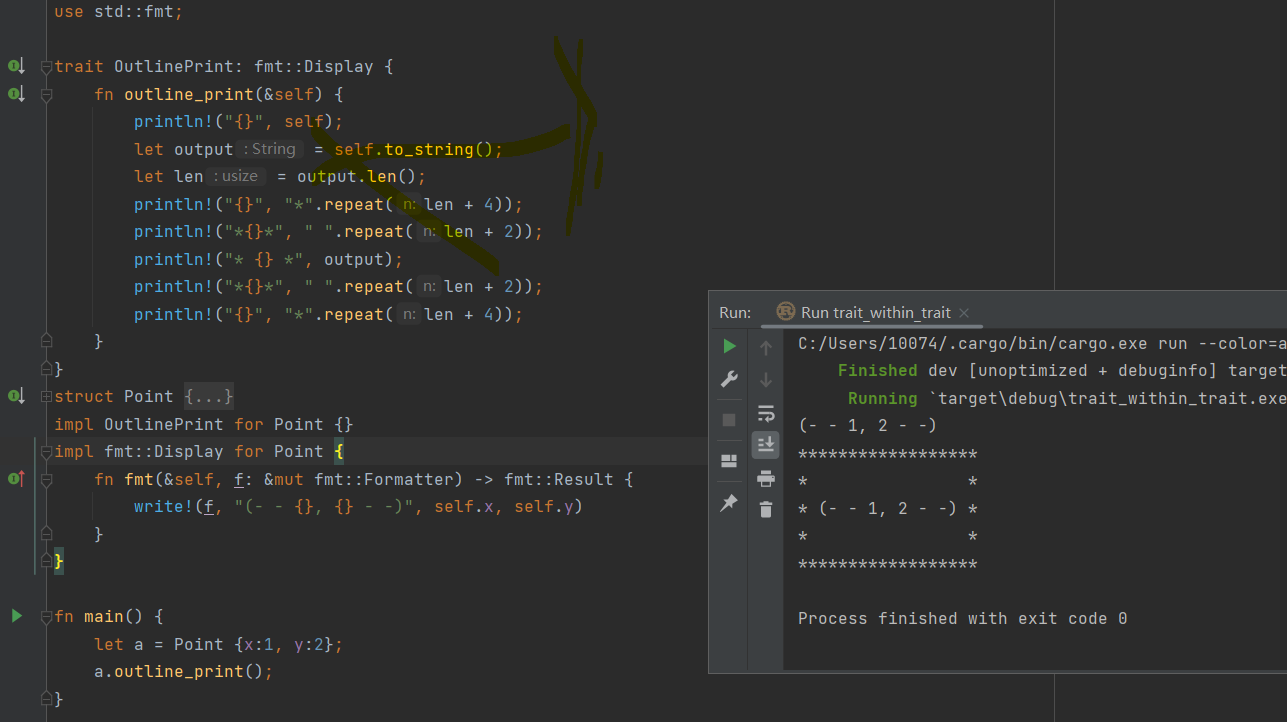
Point 若想使用 OutlinePrint 的 outline_print方法,必须同时实现 Display trait。
newtype 模式绕过孤儿规则
因rust中存在孤儿规则,其主要作用是阻止你为外部类型实现外部特质。故无法直接为 Vec 上实现 Display, 但是可通过 newtype 模式(newtype pattern),绕开这个限制。
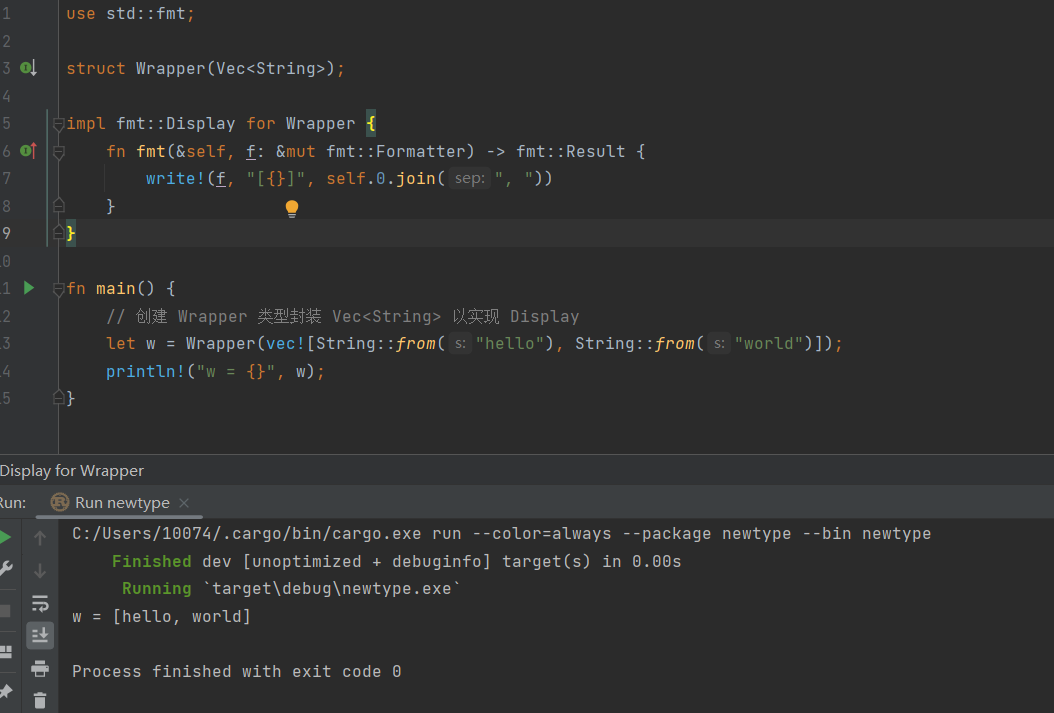
高级类型
为了类型安全和抽象而使用 newtype 模式
-
静态类型安全: newtype模式可以确保不同的包装类型不会混淆,从而提供了静态类型安全。
-
表示值的单元: newtype模式可以用于表示特定值的单位,例如米和毫米。
-
抽象实现细节: newtype可以用于隐藏内部实现细节,暴露不同的公共 API,从而提供了封装和抽象。
-
隐藏泛型类型: newtype也可以用于隐藏内部的泛型类型,从而提供更好的类型抽象。
类型别名用来创建类型同义词
可以使用 type 关键字来为现有类型提供另一个名称。
fn main() { type Kilometers = i32; // i32 类型别名 let x: i32 = 5; let y: Kilometers = 5; println!("x + y = {}", x + y); } // x + y = 10
利用类型别名减少冗长代码。
fn main() {
type Thunk = Box<dyn Fn() + Send + 'static>;
let f: Thunk = Box::new(|| println!("hi"));
fn takes_long_type(f: Thunk) {
// --snip--
}
fn returns_long_type() -> Thunk {
// --snip--
Box::new(|| ())
}
}
利用类型别名通常还与Result<T, E>类型一起用于减少重复。
use std::fmt; use std::io::Error; // pub trait Write { // fn write(&mut self, buf: &[u8]) -> Result<usize, Error>; // fn flush(&mut self) -> Result<(), Error>; // // fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>; // fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>; // } type Result<T> = std::result::Result<T, Error>; pub trait Write { fn write(&mut self, buf: &[u8]) -> Result<usize>; fn flush(&mut self) -> Result<()>; fn write_all(&mut self, buf: &[u8]) -> Result<()>; fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>; }
Rust 中的类型别名(Type Aliases)和 C++ 中的
typeof运算符有一些相似之处,但也有一些重要的区别。相似之处:
类型重命名:两者都涉及将类型重命名为另一个名称,以提高代码的可读性和模块化。
减少冗余:它们都有助于减少代码中的冗余,特别是在处理长或复杂的类型名称时。
区别:
语法和用途:
Rust 的类型别名是一种语言特性,使用
type关键字来声明,主要用于提高代码的可读性和模块化。它在编译时起作用,不提供运行时类型信息。C++ 的
typeof运算符是用于获取表达式的实际类型,它在运行时提供类型信息。它是一种运行时机制,通常用于编写与类型相关的通用代码。类型信息:
Rust 的类型别名不提供对类型信息的访问,它只是一种更改类型名称的方式。
C++ 的
typeof运算符用于检索表达式的实际类型信息,允许程序员在运行时获取有关类型的信息。编程范式:
Rust 的类型别名主要用于静态类型检查,与Rust的静态类型系统一起使用。
C++ 的
typeof运算符更适用于传统的动态类型语言,用于在运行时处理类型信息。总的来说,尽管它们都涉及到类型的更名或别名,但 Rust 中的类型别名主要用于提高代码可读性和模块化,而 C++ 中的
typeof运算符用于运行时获取类型信息。这些是两种不同的机制,适用于不同的编程语言和用途。
never 类型
Rust 有一个叫做!的特殊类型。它没有任何值也被称为空类型(empty type),返回值为!的函数称为发散函数。
fn bar() -> ! {
// --snip--
panic!();
}
continue 为!类型。match分支必须返回相同的类型,而!类型的表达式可以强制转换为任何其他类型,故可以在match中使用。
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
panic!同样也是!类型,因此可以在match中使用。
enum Option<T> {
Some(T),
None,
}
use crate::Option::*;
impl<T> Option<T> {
pub fn unwrap(self) -> T {
match self {
Some(val) => val,
None => panic!("called `Option::unwrap()` on a `None` value"),
}
}
}
loop 表达式也是!类型。
fn main() { print!("forever "); loop { print!("and ever "); } }
因为循环永远也不结束,所以此表达式的值是 !。
动态大小类型和 Sized trait
在Rust中,动态大小类型「DST」指的是具有在运行时才能确定大小的类型,例如str。这些类型的大小在编译时无法确定,因此不能创建直接包含这些类型的变量。Rust要求所有类型在编译时都有已知的大小,以便为值分配足够的内存。
fn main() {
let s1: str = "Hello there!";
let s2: str = "How's it going?";
//error[E0308]: mismatched types
}
因为str是一个DST,其大小在编译时无法确定。这会导致编译错误(error[E0308]: mismatched types),因为Rust要求所有类型在编译时必须具有已知的大小。需使用&str代替str。slice 数据结构仅存储slice的起始位置和长度。
动态大小类型的黄金规则:必须将动态大小类型的值置于某种指针之后。为了处理 DST,Rust 有一个特定的 trait 来决定一个类型的大小是否在编译时可知:这就是 Sized trait。这个 trait 自动为编译器在编译时就知道大小的类型实现。
高级函数与闭包
函数指针
通过函数指针允许我们使用函数作为另一个函数的参数。函数的类型是 fn (使用小写的 「f」 )以免与 Fn 闭包 trait 相混淆。fn 被称为 函数指针(function pointer)。
fn add_one(x: i32) -> i32 { x + 1 } fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 { f(arg) + f(arg) } fn main() { let answer = do_twice(add_one, 5); println!("The answer is: {}", answer); } // The answer is: 12
与闭包不同,fn 是一种类型而不是特性,因此我们直接指定 fn 作为参数类型,而不是声明具有 Fn 特性之一的通用类型参数作为特性约束。
函数指针实现了闭包 trait(Fn、FnMut 和 FnOnce)中的所有三种,因此可以将函数指针作为预期闭包的参数传递给函数。当与不支持闭包的外部代码进行交互时,C 函数可以接受函数作为参数,但 C 不支持闭包。
返回闭包
闭包表现为 trait,这意味着不能直接返回闭包。
fn main() {
println!("- - -");
}
fn returns_closure() -> dyn Fn(i32) -> i32 {
|x| x + 1
}
// error[E0746]: return type cannot have an unboxed trait object
// --> src\main.rs:4:25
// |
// | fn returns_closure() -> dyn Fn(i32) -> i32 {
// | ^^^^^^^^^^^^^^^^^^ doesn't have a size known at compile-time
根据错误提示可知 Rust 不知道存储闭包需要多少空间。修改代码:
fn main() {
let closure = returns_closure();
let result = closure(5);
println!("Result: {}", result);
}
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}
// Result: 6
宏
在Rust中,宏(macro)是一组功能,包括用 macro_rules! 定义的声明式宏和三种类型的过程宏:
-
自定义
#[derive]宏,用于通过结构体和枚举上的derive属性生成代码。 -
类属性的宏,用于定义可用于任何项上的自定义属性。
-
类函数的宏,看起来像函数调用,但操作其参数中指定的标记。
宏和函数的区别
从根本上讲,宏是一种编写生成其他代码的代码的方式,这被称为元编程。元编程对于减少需要编写和维护的代码量非常有用,这也是函数的作用之一。宏和函数在 Rust 中有一些重要的区别:
-
代码生成和操作能力:宏允许你生成和操作代码,而函数则执行特定的操作。宏通常用于代码生成、元编程和在编译期间进行代码操作,而函数则用于在运行时执行操作。
-
参数数量和类型:函数必须具有已知数量和类型的参数,而宏可以接受可变数量的参数,包括不同类型的参数。这使得宏能够更加灵活地处理各种输入。
-
编译时与运行时:宏在编译时展开,生成代码,而函数在运行时执行。这使得宏能够执行一些函数无法完成的任务,如实现 trait 或生成代码。
-
作用范围:你必须在使用宏之前先定义或引入它们,而函数可以在代码的任何位置定义和调用。
-
复杂性和可读性:宏定义通常比函数定义更复杂,因为你在编写代码来生成代码。这可能会降低宏的可读性和维护性。
使用 macro_rules! 声明宏
Rust 最常用的宏形式是 声明宏(declarative macros),它允许你以类似 Rust 的 match 表达式的方式编写宏。下面为vec! 的宏定义:
macro_rules! vec {
() => (
$crate::__rust_force_expr!($crate::vec::Vec::new())
);
($elem:expr; $n:expr) => (
$crate::__rust_force_expr!($crate::vec::from_elem($elem, $n))
);
($($x:expr),+ $(,)?) => (
$crate::__rust_force_expr!(<[_]>::into_vec(
// This rustc_box is not required, but it produces a dramatic improvement in compile
// time when constructing arrays with many elements.
$crate::boxed::Box::new([$($x),+])
))
);
}
以下是它的主要部分:
-
macro_rules! vec:这是宏定义的开始。 -
()模式:当宏没有参数时,生成一个新的空向量。 -
($elem:expr; $n:expr)模式:当宏接受两个参数时,根据给定的元素表达式$elem和元素数量$n,生成一个新的向量。 -
($($x:expr),+ $(,)?)模式:当宏接受一个或多个元素表达式时,生成一个新的向量。这是宏的最常见用法。
用于从属性生成代码的过程宏
use proc_macro; #[some_attribute] //占位符 pub fn some_name(input: TokenStream) -> TokenStream { }
定义过程宏的函数以 TokenStream 作为输入并产生 TokenStream 作为输出。在同一crate 中可以有多种类型的过程宏。
如何编写自定义 derive 宏
首先创建以下内容:
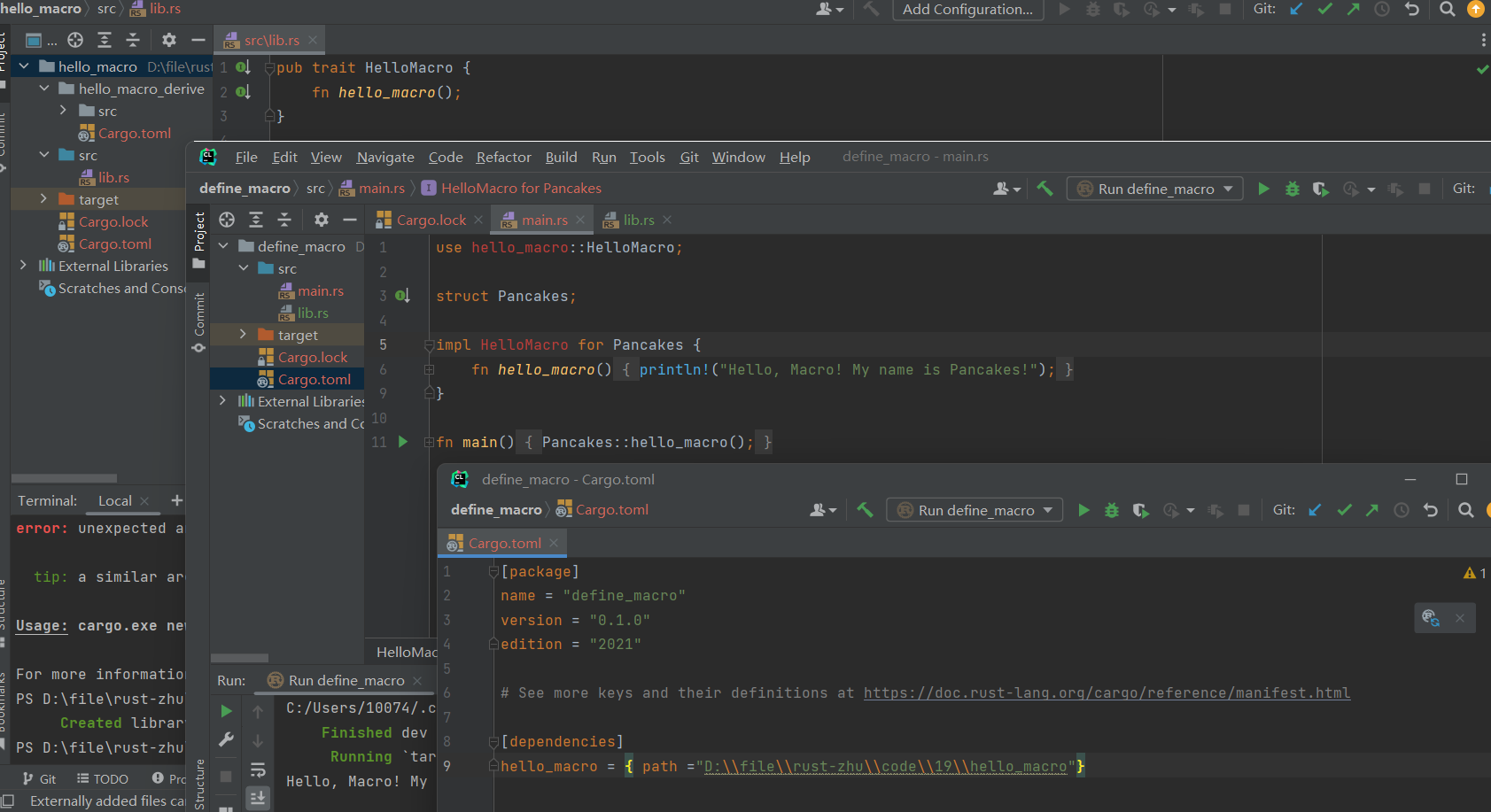
下一步是定义过程宏。在hello_macro中创建名为 hello_macro_derive 的新 crate,并修改其 Cargo.toml:

并添加如下内容到 hello_macro_derive crate 的 src/lib.rs 文件中,hello_macro_derive 函数函数负责解析 TokenStream。
use proc_macro::TokenStream;
use quote::quote;
use syn;
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a representation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implementation
impl_hello_macro(&ast)
}
hello_macro_derive 函数将在我们的库的用户在类型上指定 #[derive(HelloMacro)] 时被调用。同时syn crate 将 Rust 代码从字符串解析为数据结构,我们可以对其执行操作。quote crate 将 syn 数据结构转换回 Rust 代码。impl_hello_macro 负责生成新的 Rust 代码。
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let gen = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My name is {}!", stringify!(#name));
}
}
};
gen.into()
}
struct定义如下:
pub struct DeriveInput {
pub attrs: Vec<Attribute>,
pub vis: Visibility,
pub ident: Ident,
pub generics: Generics,
pub data: Data,
}
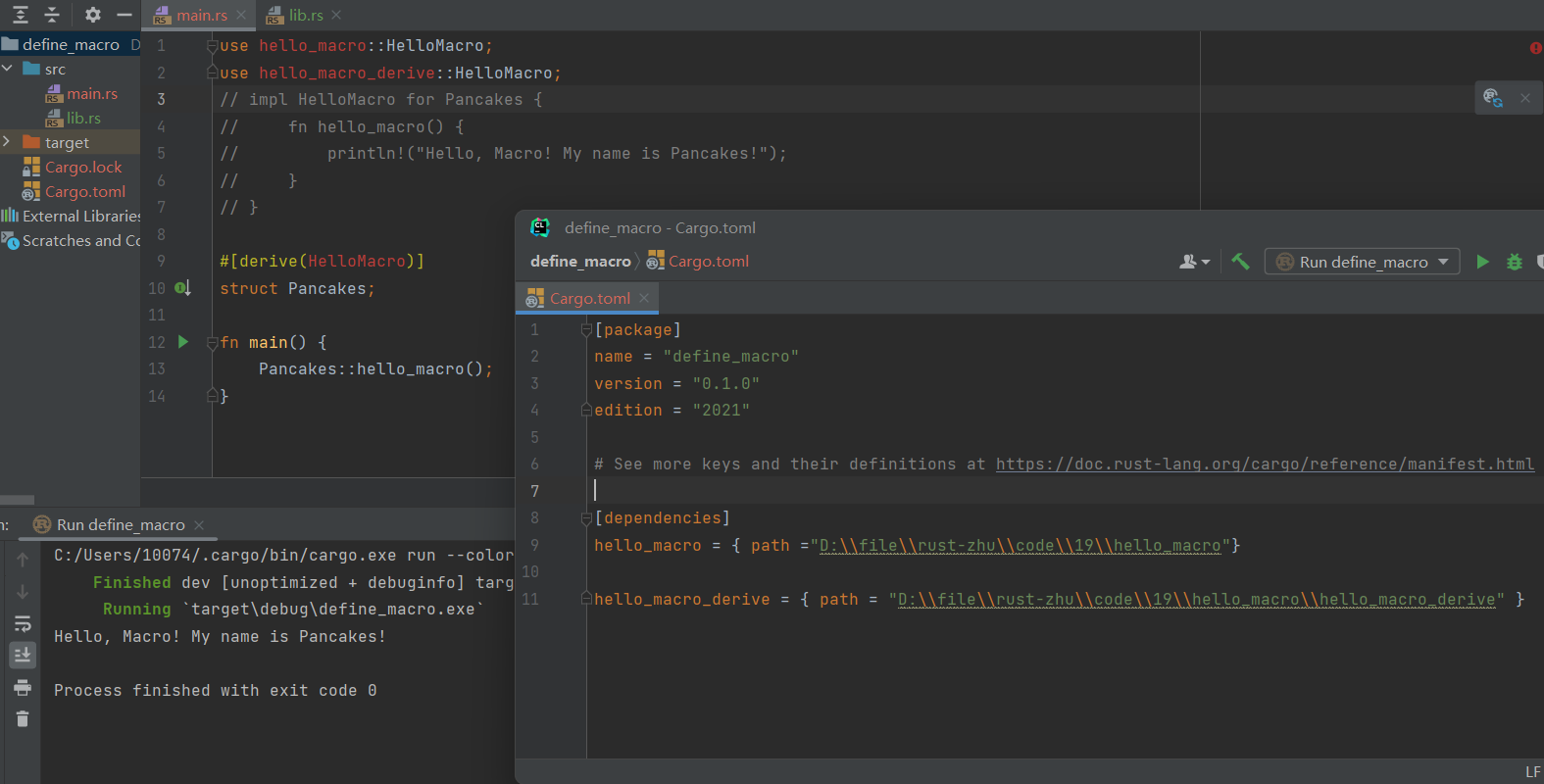
hello_macro_derive crate 代码截图:
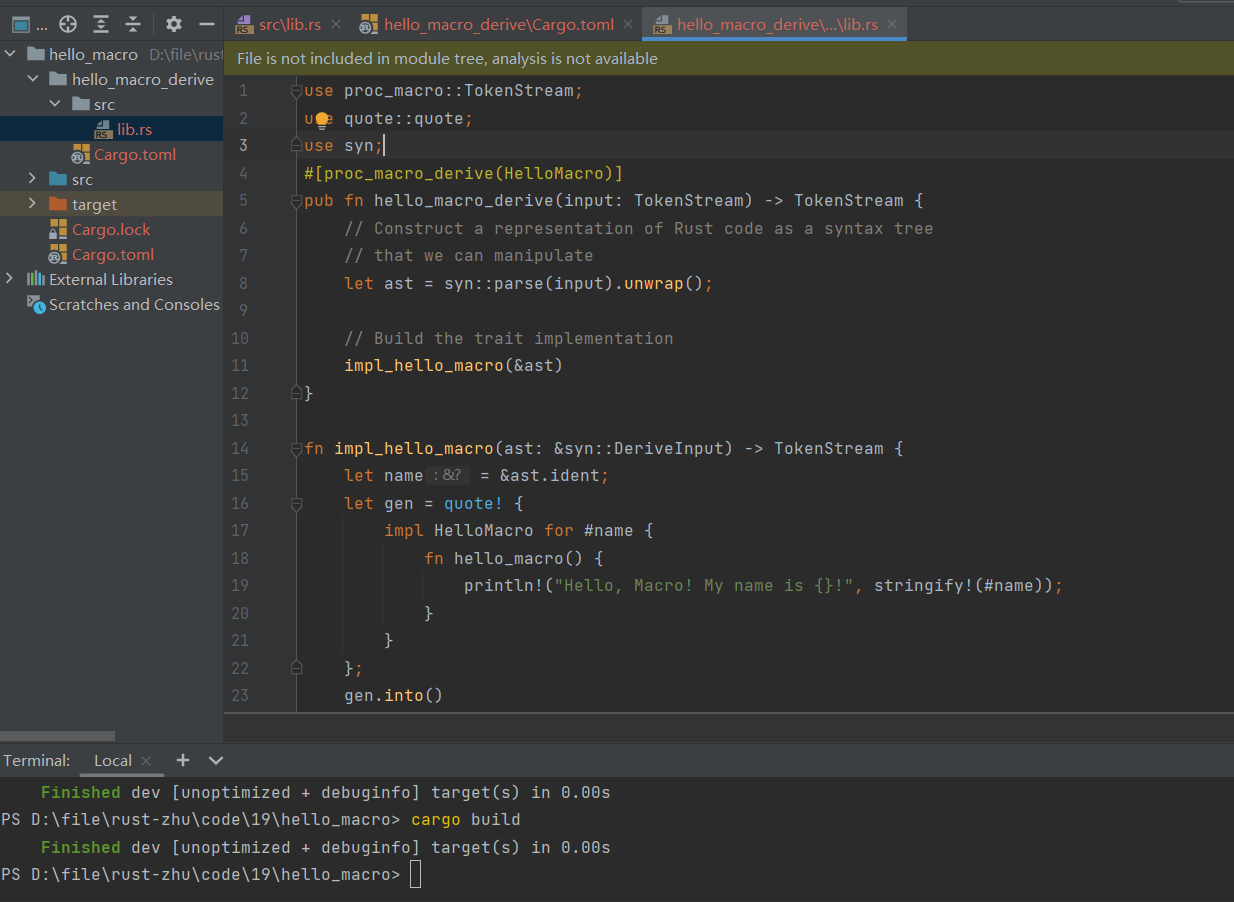
运行图以及相关依赖:
类属性宏
类属性宏(Attribute-like macros)与自定义派生宏相似,但不是为derive属性生成代码,而是允许你创建新的属性。derive只适用于结构体和枚举;而属性宏也可以应用于其他项,比如函数。
可创建一个名为 route 的属性用于注解 web 的函数:
#[route(GET, "/")] fn index() { // ... }
这个 #[route] 属性将由框架定义为一个过程宏。宏定义函数的签名如下:
#[proc_macro_attribute] pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream { // ... }
在这里有两个类型为 TokenStream 的参数。第一个用于属性的内容:GET, "/" 部分。第二个是属性所标记的项,此处为index()。
类函数宏
类函数宏定义看起来像函数调用的宏。例如,sql! 宏可能像这样被调用:
let sql = sql!(SELECT * FROM posts WHERE id=1);
sql! 宏的定义如下:
pub fn sql(input: TokenStream) -> TokenStream {
// ...
}

文章评论