泛型,处理重复的工具。
泛型允许我们用表示多种类型的占位符替换特定类型,以消除代码重复。
泛型
我们使用泛型来为函数签名或结构等项创建定义,然后可以将其用于许多不同的具体数据类型。
在函数定义中
在定义使用泛型的函数时,我们将泛型放在函数的签名中,通常在这里指定参数和返回值的数据类型。
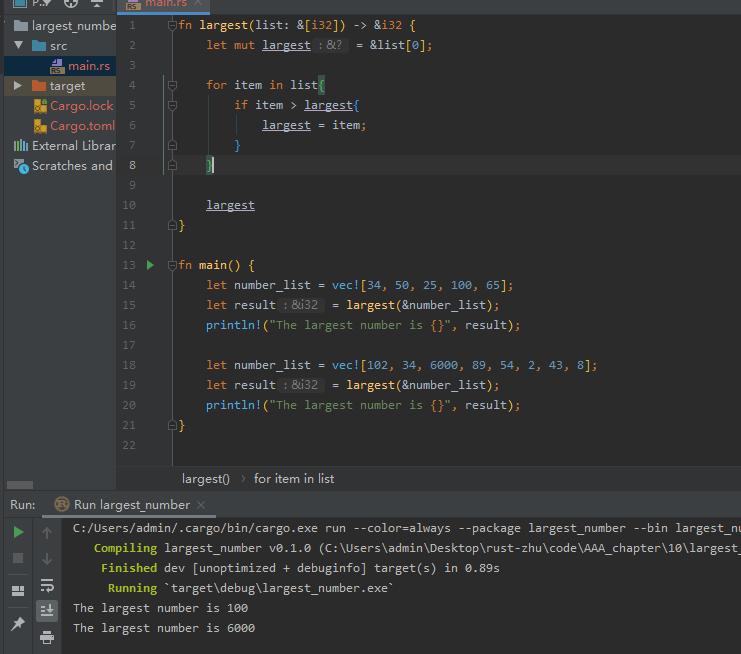
不使用泛型时:
泛型函数定义:
fn largest<T>(list: &[T]) -> &T {}
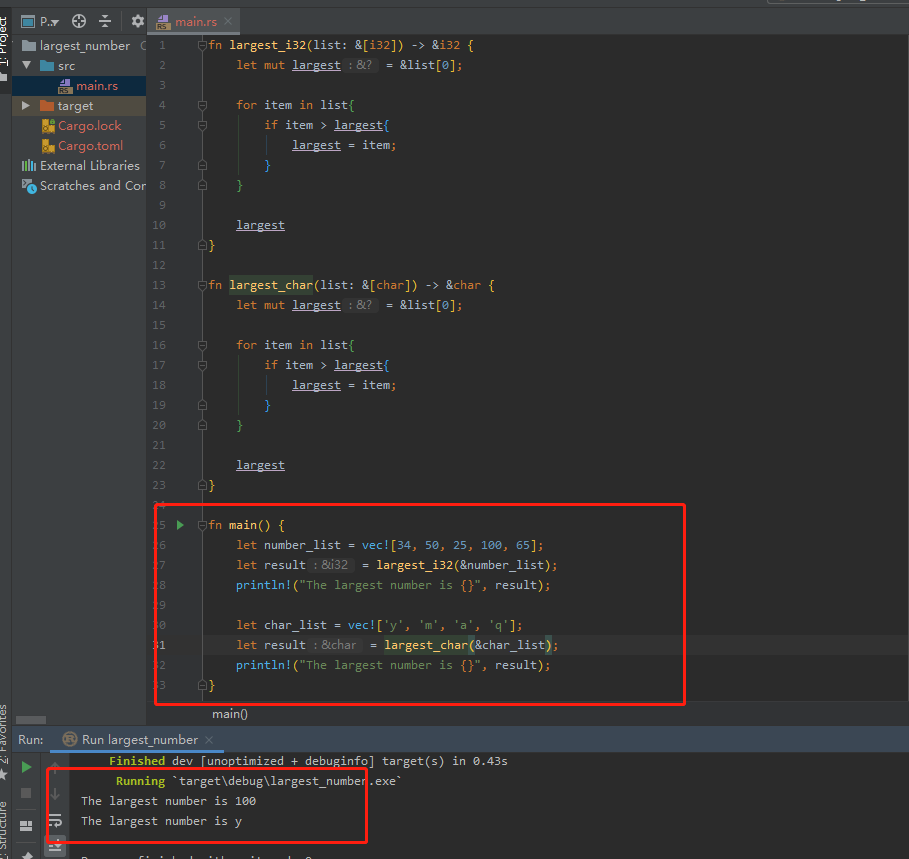
函数最大是对某种类型T的泛型。该函数有一个名为list的形参,它是类型T的值的切片。最大函数将返回对相同类型T的值的引用。
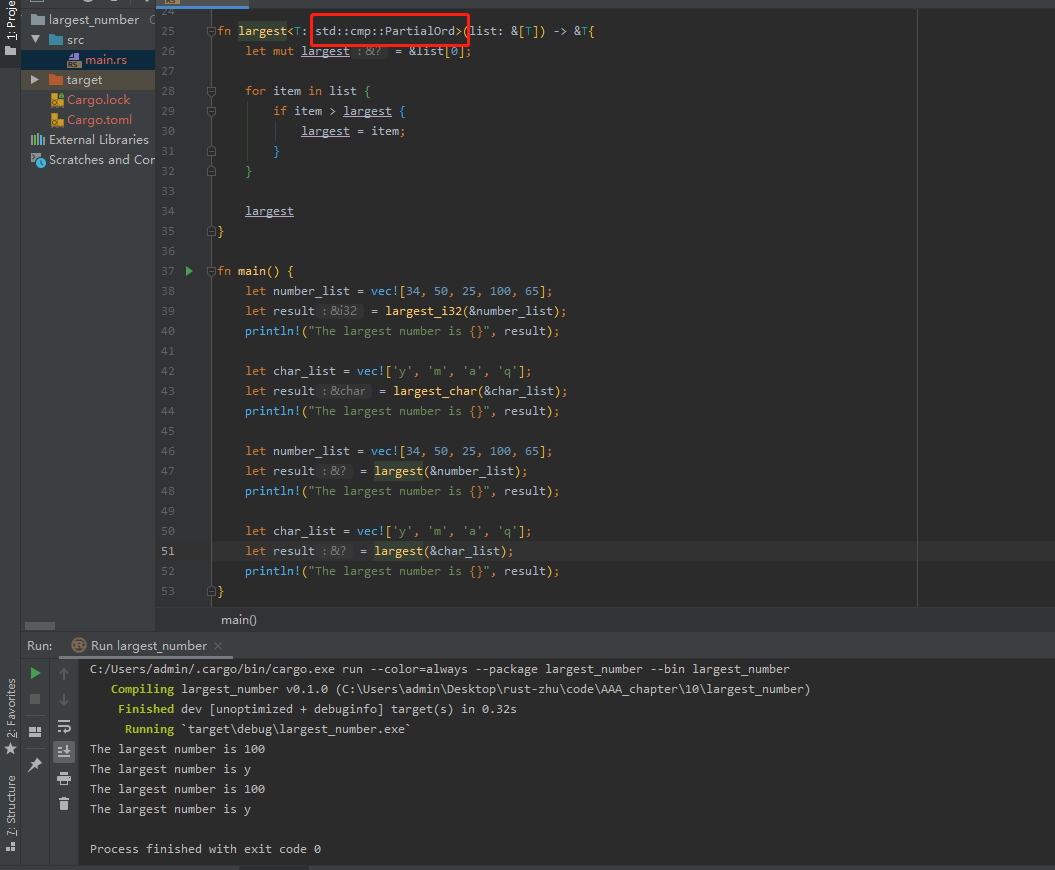
std::cmp::PartialOrd 是 Rust 标准库中的一个 trait,它提供了一种比较类型实例的方法。该 trait 定义了关系运算符(例如小于号(<))的行为。
实现 std::cmp::PartialOrd trait 的类型可以使用这些关系运算符进行比较。这些比较可以用于实现排序算法,例如,您可以使用比较运算符对一组数据进行排序。
在结构定义中
可以使用<>语法定义结构,在一个或多个字段中使用泛型类型参数。
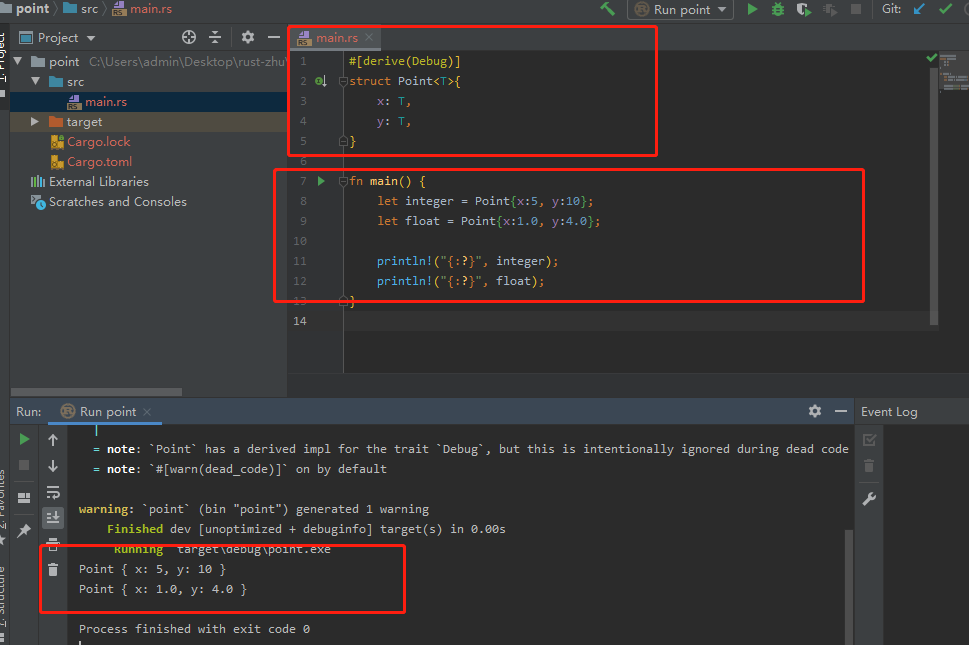
x和y都是泛型,但可以有不同的类型,可以使用多个泛型类型参数、
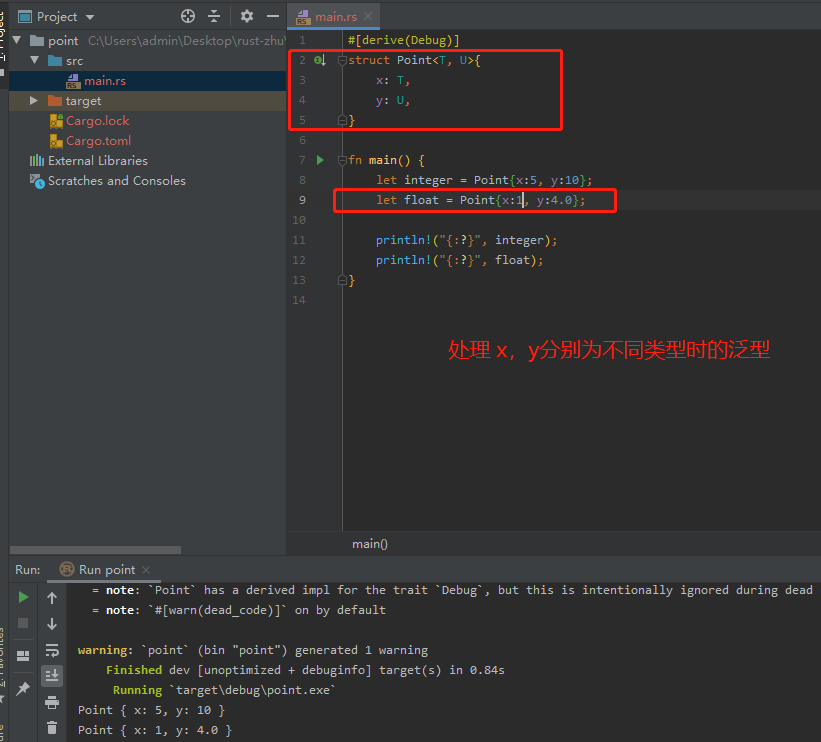
在枚举定义中
同处理结构体一样,我们可以定义枚举来保存泛型数据类型的变体。例如Option<T>枚举。
enum Option<T> {
Some(T),
None,
}
Result枚举是两种类型T和E的泛型,并且有两个变体,
在方法定义中
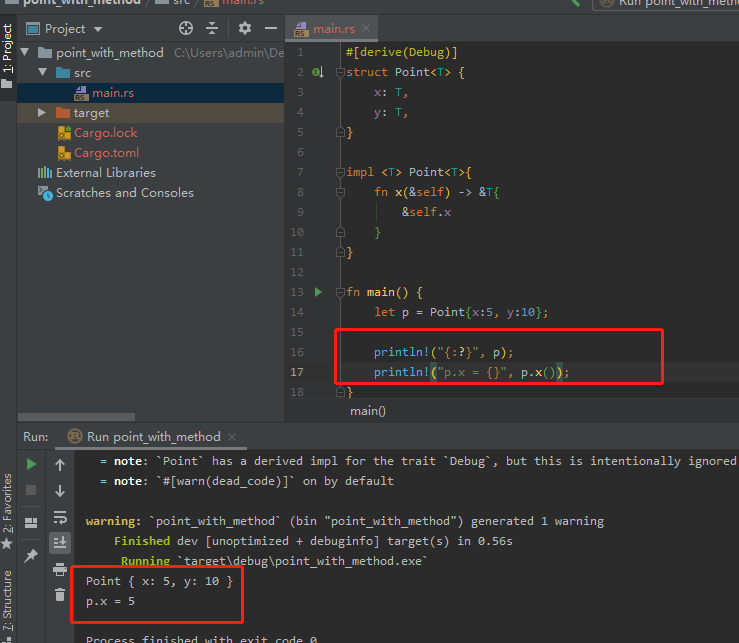
在Point<T>上定义了一个名为x的方法,该方法返回对字段x中的数据的引用。
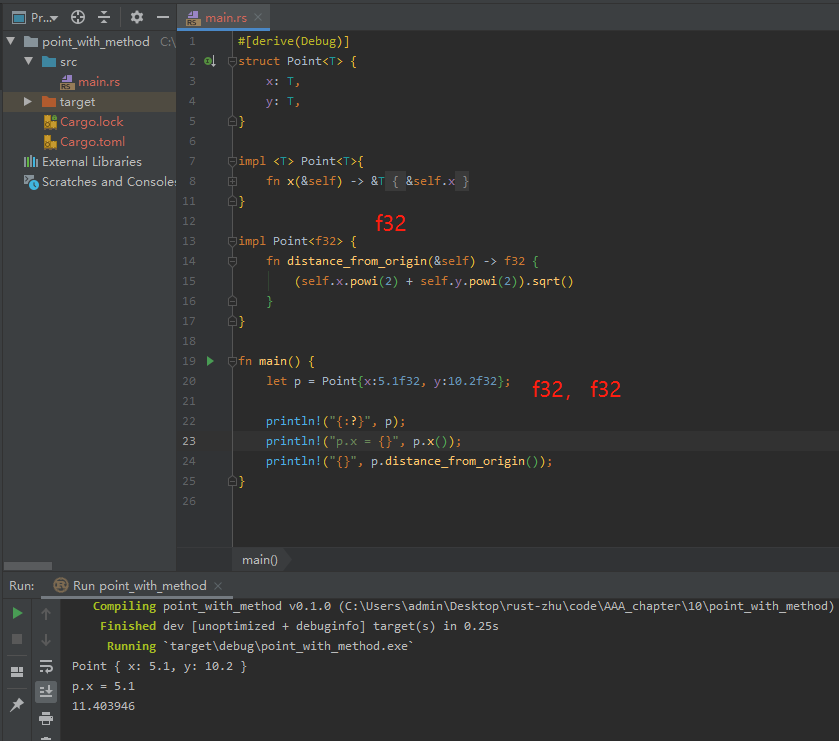
该方法测量我们的点到坐标(0.0,0.0)处的点的距离,并使用仅适用于浮点类型的数学操作。类型不符时产生的问题:
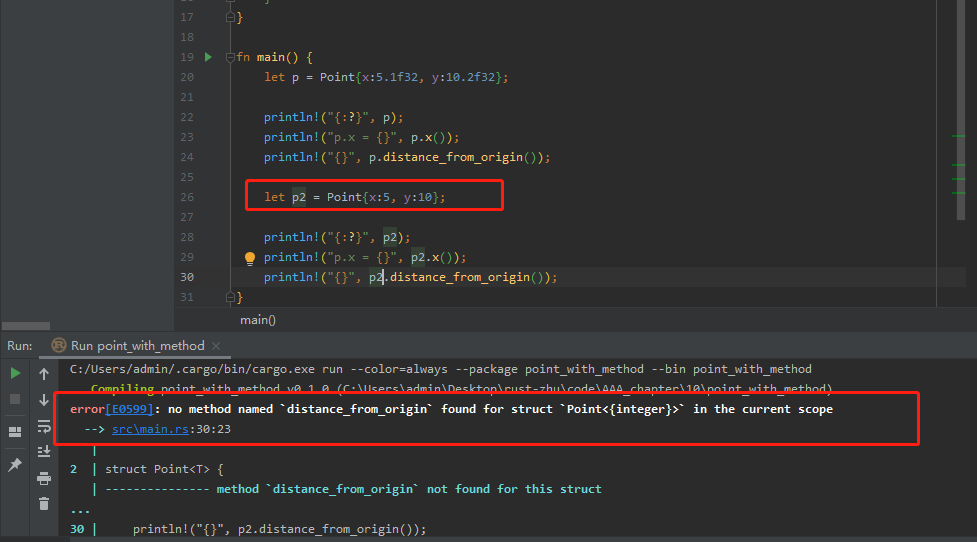
结构定义中的泛型类型参数并不总是与在同一结构的方法签名中使用的参数相同。具体如下:

使用泛型的代码性能
使用泛型类型不会使程序比使用具体类型运行得更慢。Rust通过在编译时使用泛型执行代码的单一化来实现这一点。单一化是通过填充编译时使用的具体类型,将泛型代码转换为特定代码的过程。
fn main() {
let integer = Some(5);
let float = Some(5.0);
}
当Rust编译这段代码时,它执行单化。在这个过程中,编译器读取Option<T>实例中使用的值,并识别出两种Option<T>:一种是i32,另一种是f64。因此,它将Option<T>的泛型定义扩展为两个专门用于i32和f64的定义,从而将泛型定义替换为特定的定义。
enum Option_i32 {
Some(i32),
None,
}
enum Option_f64 {
Some(f64),
None,
}
fn main() {
let integer = Option_i32::Some(5);
let float = Option_f64::Some(5.0);
}
泛型Option<T>
Trait:定义共享行为
trait定义了特定类型所具有的功能,并且可以与其他类型共享。我们可以用特征来抽象地定义共享行为。我们可以使用trait边界来指定泛型类型可以是具有特定行为的任何类型。
注意:trait类似于其他语言中称为接口的特性,尽管有一些不同。
定义一个Trait
类型的行为由我们可以调用该类型的方法组成。如果我们可以对所有这些类型调用相同的方法,不同的类型就会共享相同的行为。Trait定义是一种将方法签名分组在一起的方法,以定义完成某些目的所必需的一组行为。
pub trait Summary {
fn summarize(&self) -> String;
}
trait关键字和一个名称来声明trait。我们还将这个trait声明为pub,这样依赖于这个crate的crate也可以使用这个trait,正如我们将在几个例子中看到的那样。
在方法签名之后,我们使用分号,而不是在花括号内提供实现。实现此特征的每个类型必须为方法体提供自己的自定义行为。
trait的主体中可以有多个方法:每行列出一个方法签名,每行以分号结束。
实现一个Trait
在impl之后,我们放入想要实现的trait名称,然后使用for关键字,然后指定想要为其实现trait的类型的名称。
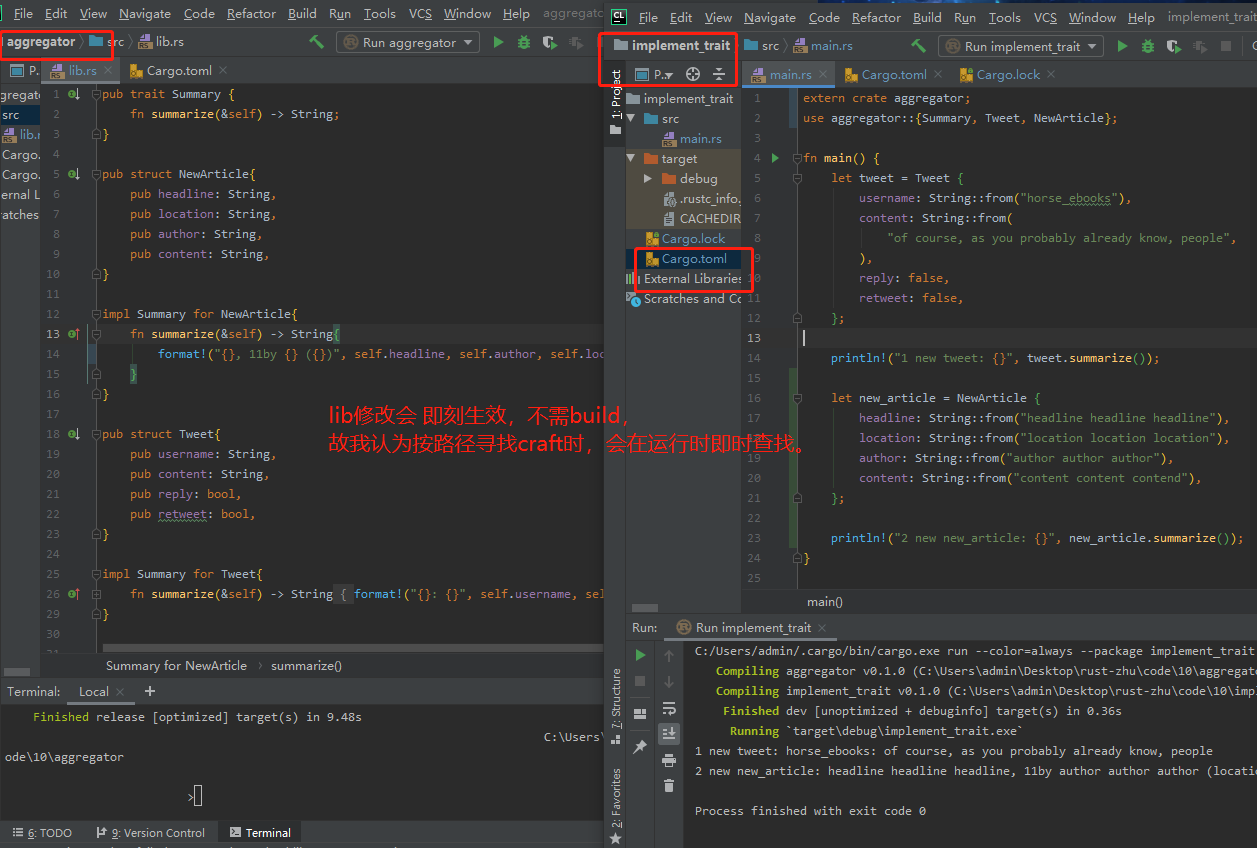
lib位置,以及Cargo.toml中配置
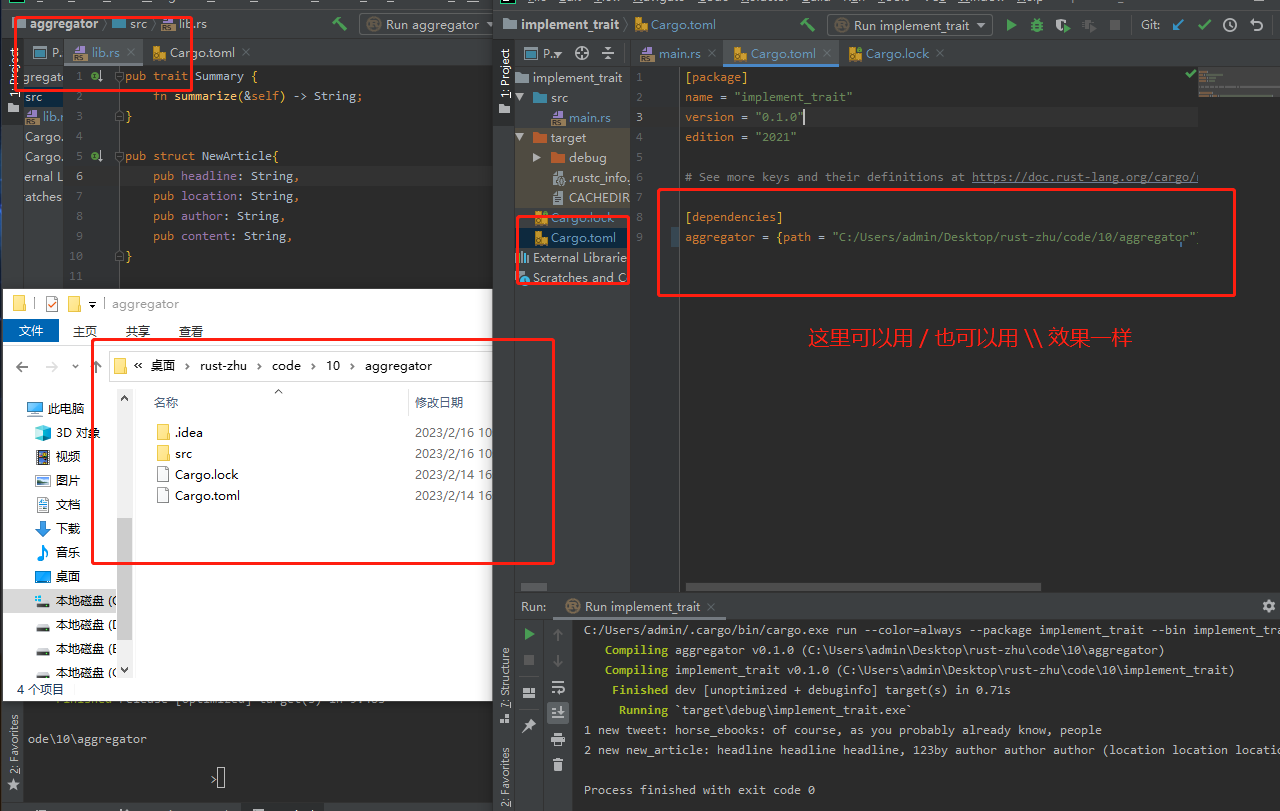
默认实现
为trait中部分或所有方法设置默认行为,而不是要求每种类型的所有方法都实现默认行为很有用。只需实现非默认的行为。
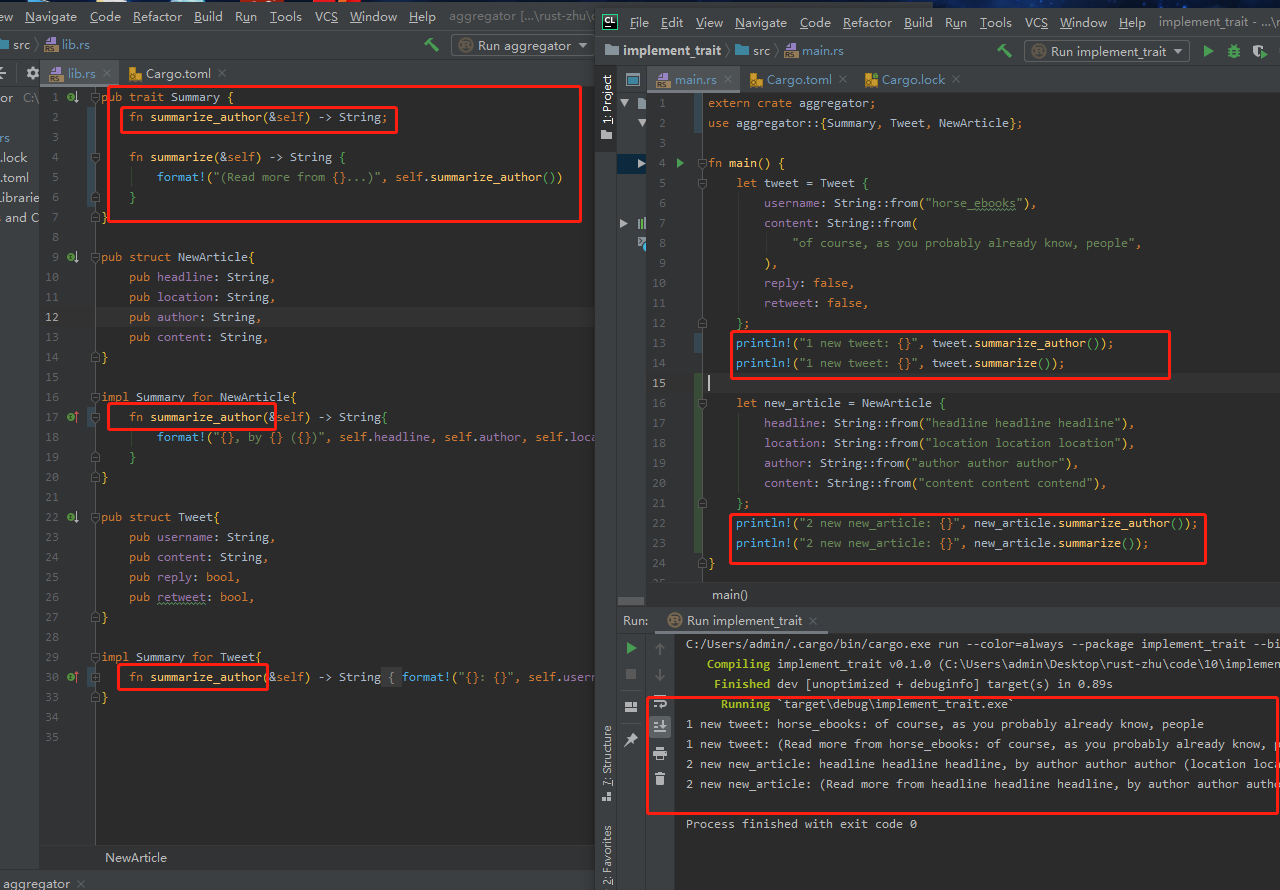
默认方法不需要在特定结构中实现就可以使用。同时默认方法可在特定结构里重写。

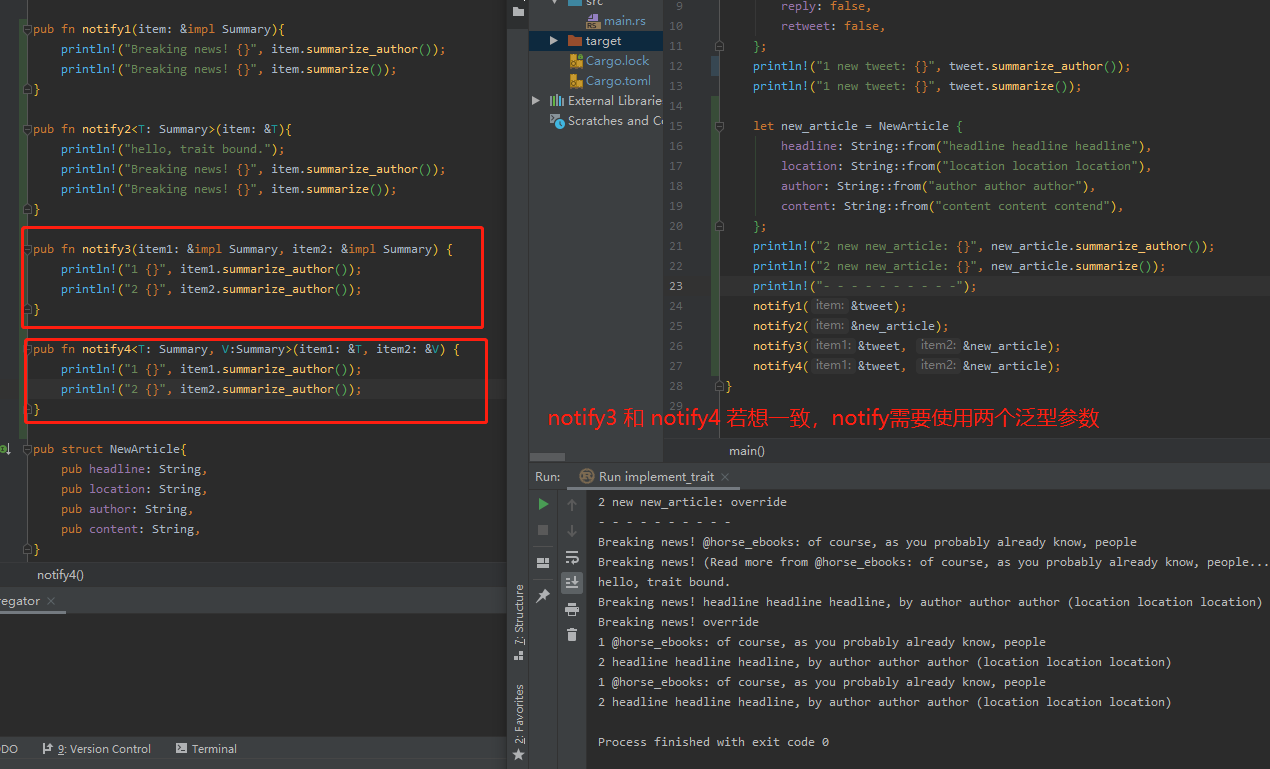
特征作为参数
使用特征来定义接受多种不同类型的函数。
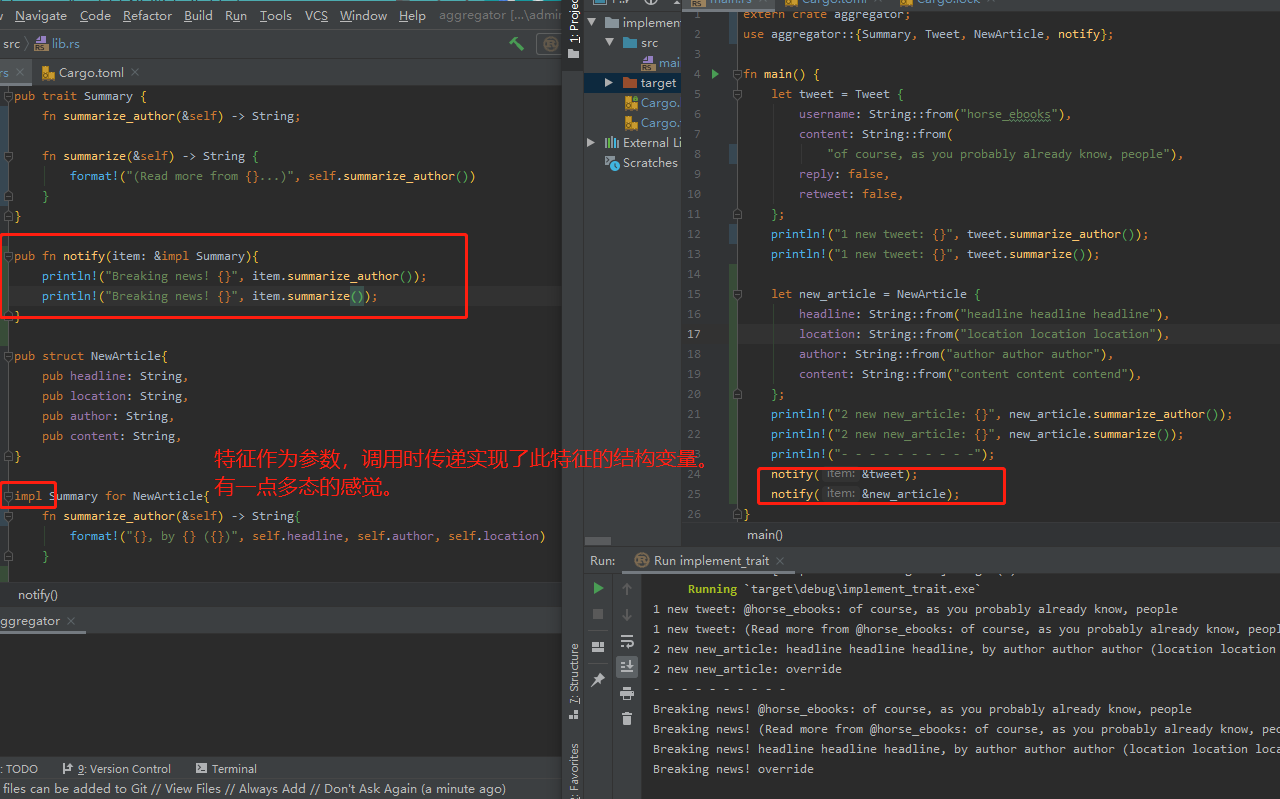
Trait Bound语法
pub fn notify<T: Summary>(item: &T){
println!("Breaking news! {}", item.summarize());
}
单参数:
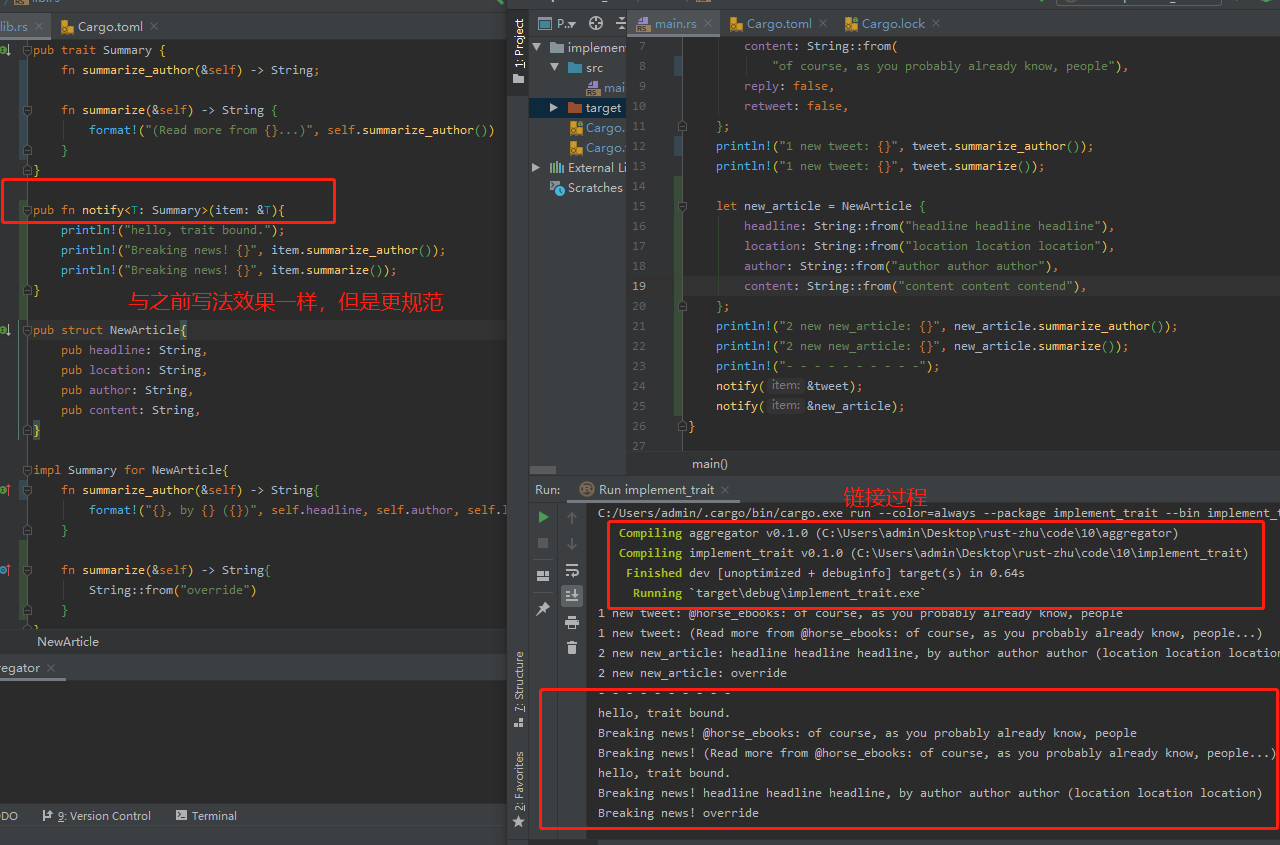
多参数:
若想限制只能同一结构,可以只是用一个泛型参数T。
使用+语法指定多个Trait Bounds
感觉就类似于实现多个接口。
普通格式:
pub fn notify(item: &(impl Summary + Display)) {
泛型格式(更好):
pub fn notify<T: Summary + Display>(item: &T) {
使用where子句明确Trait Bounds
每个泛型都有自己的trait bounds,因此具有多个泛型类型参数的函数在函数名和参数列表之间可能包含大量trait bounds信息,使得函数签名难以阅读。出于这个原因,Rust在函数签名之后的where子句中使用了另一种语法来指定trait bounds。
不推荐的写法:
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {
更推荐的写法:
fn some_function<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}
返回类型为特征
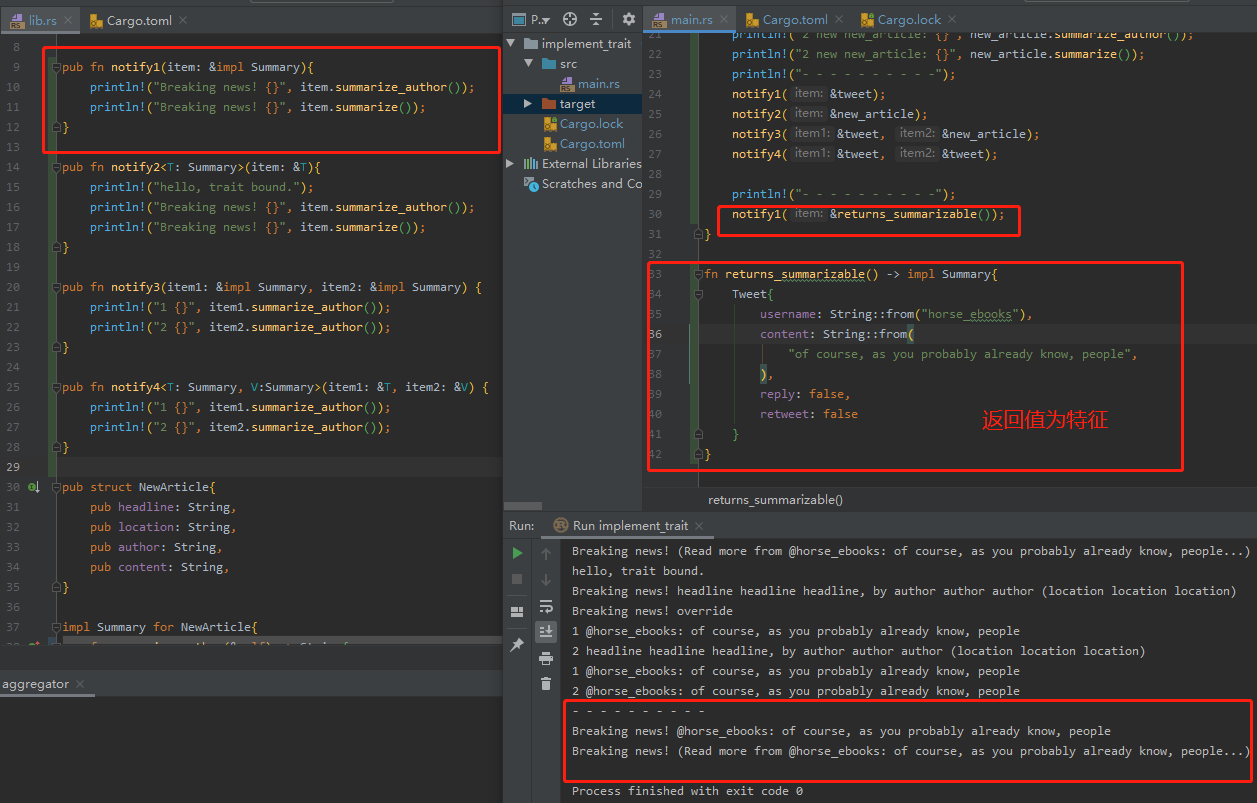
若想返回属于此特征的单个类型,使用if-else会产生如下错误:if and else have incompatible types 原因是:当 switch 为真时返回了一个 NewArticle 类型的值,当 switch 为假时返回了一个 Tweet 类型的值。由于这两个类型都实现了 Summary trait,因此我们可以将它们统一用 impl Summary 来返回。然而,由于 NewArticle 和 Tweet 的类型不同,导致了 if 和 else 两个分支的返回类型不一致,因此编译器会报错。
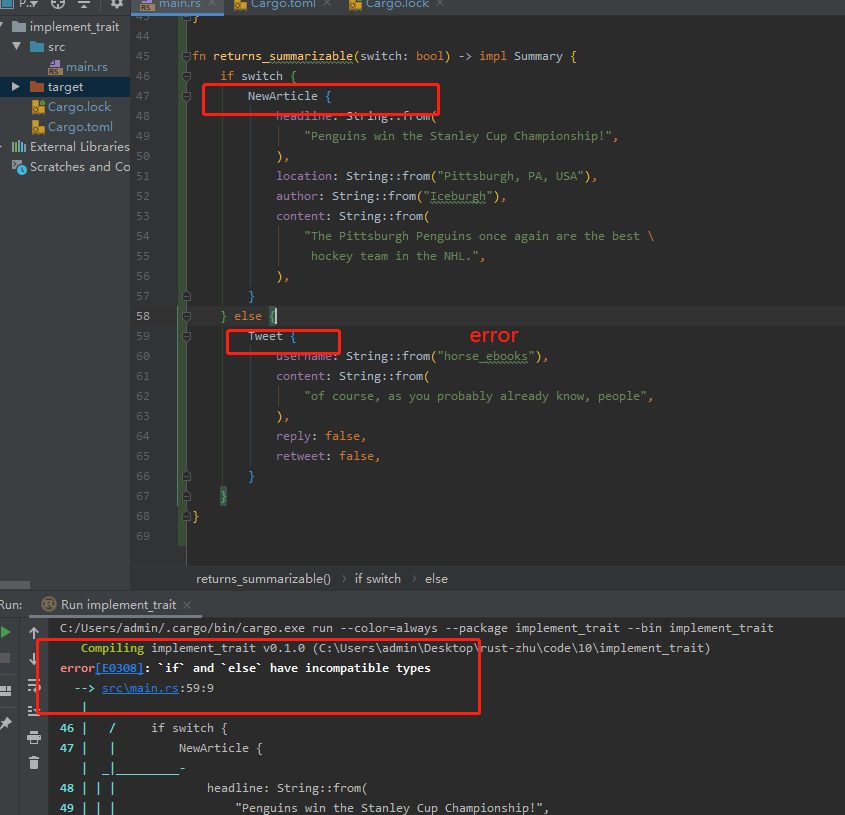
正确写法:返回类型改为 Box<dyn Summary>,其中 dyn 是 Rust 中表示 trait 对象的关键字。这个函数现在可以正常运行,而且它可以在运行时动态选择要返回的类型,这也是 trait 对象的一个优点。
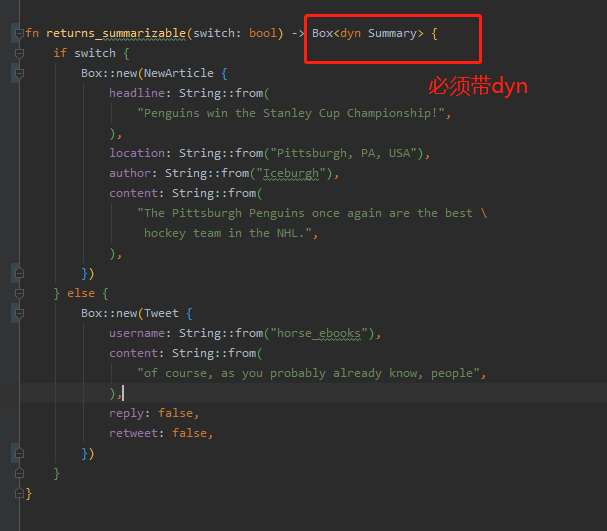
Box<dyn Summary> 表示一个指向实现了 Summary trait 的类型的堆上分配对象的指针,由 Box 类型进行管理。其中,dyn 是 Rust 的关键字,表示动态分发(dynamic dispatch),也就是运行时才决定调用哪个实现。
在 Rust 中,由于不同的类型大小可能不同,因此不能在栈上直接存储一个具体类型的值。通过使用 Box 类型可以在堆上分配空间来存储一个值,并将这个值的所有权交给 Box,由 Box 负责管理这块内存,以确保在所有权范围之外时释放这块内存。
在这个例子中,Box<dyn Summary> 表示一个实现了 Summary trait 的类型的堆上分配对象的指针,可以指向实现 Summary trait 的任意类型的对象,由 Box 类型进行所有权管理。由于 dyn 表示动态分发,所以当你调用对象的方法时,Rust 在运行时才决定具体调用哪个实现。
关于Box<T>、Box<dyn Trait>和 * :
1: Box<T> 类型可以通过解引用操作符 * 来获取其底层的值 T,但是这只适用于那些在编译时已知大小的类型,例如整数、浮点数、指针等。因为在 Rust 中,解引用操作符会尝试将一个指针类型解引用为其指向的值类型,然后将其复制到一个栈上的变量中,而这个栈上的变量必须具有已知的大小。而在 Rust 中,String 类型和 &str 类型的大小都是在运行时动态分配的,因此不能直接使用解引用操作符来获取它们的值。
2: 在使用 Box<dyn Trait> 时,通常情况下不需要使用解引用操作符 *,因为 Box<T> 类型会自动解引用为 T 类型。这意味着你可以直接调用 Box<dyn Trait> 实例上的方法,就好像它是实现了 Trait 特征的结构体一样。因此,如果你想要调用 Box<dyn Trait> 实例上的方法,可以直接使用点号操作符来调用,而不需要使用 * 来解引用。( 也可以手动解引用,(*).function() )
关于从Box<dyn Trait> 类型的值转换为具体的实现类型
downcast 方法来尝试将 Box<dyn Trait> 类型的值转换为具体的实现类型,如果成功,则返回一个 Box<T> 类型的值,其中 T 是实现了 Trait 特征的类型。如果转换失败,则返回一个 Err 类型的值。
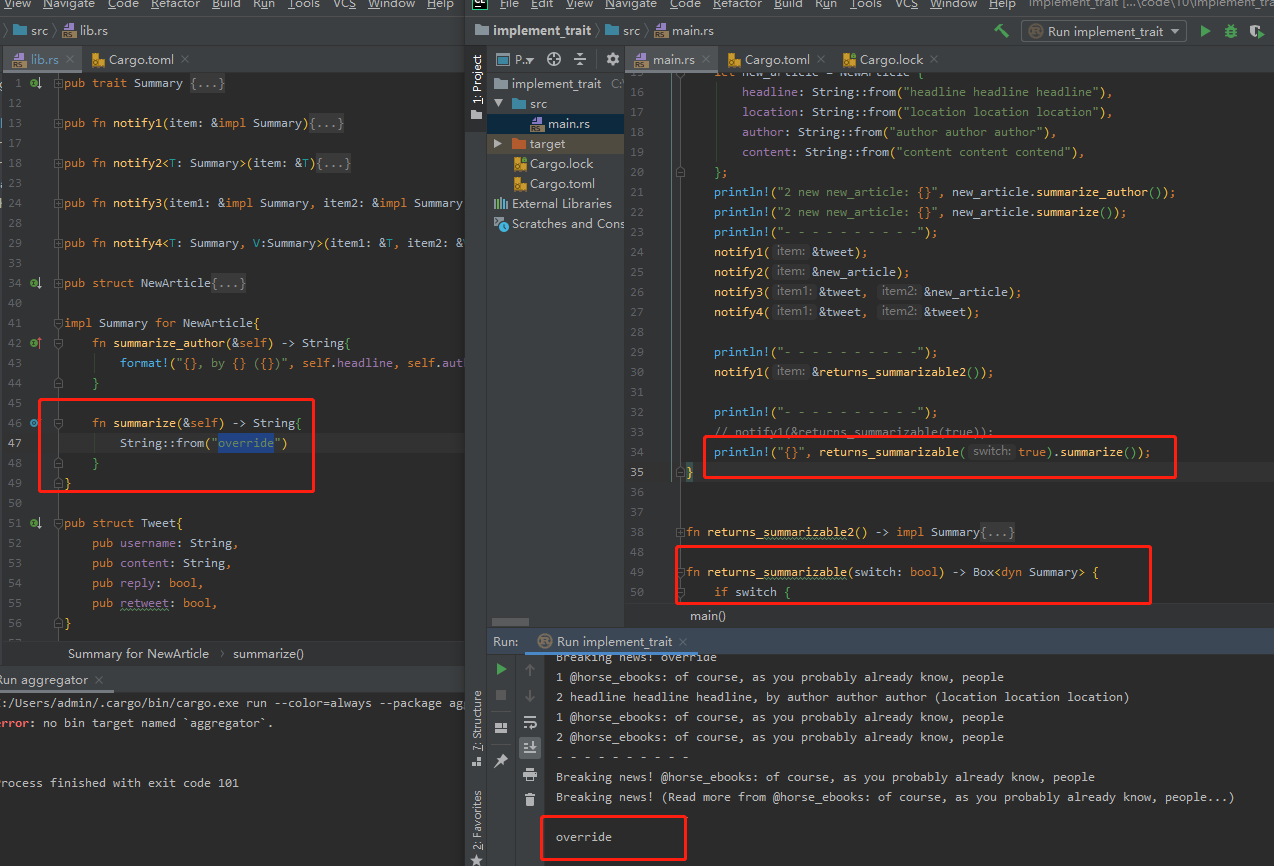
函数返回特征,通过特征(接口 多态?)可以使用对应的方法。若想将特征转为struct可以使用downcast 。但downcast 方法只能用于将 Any 类型的对象转换为其实际类型,不能用于将 trait object 转换为其实际类型。这是因为 trait object 中不包含实际类型信息,所以无法进行动态类型转换。
常量类型使用downcast:
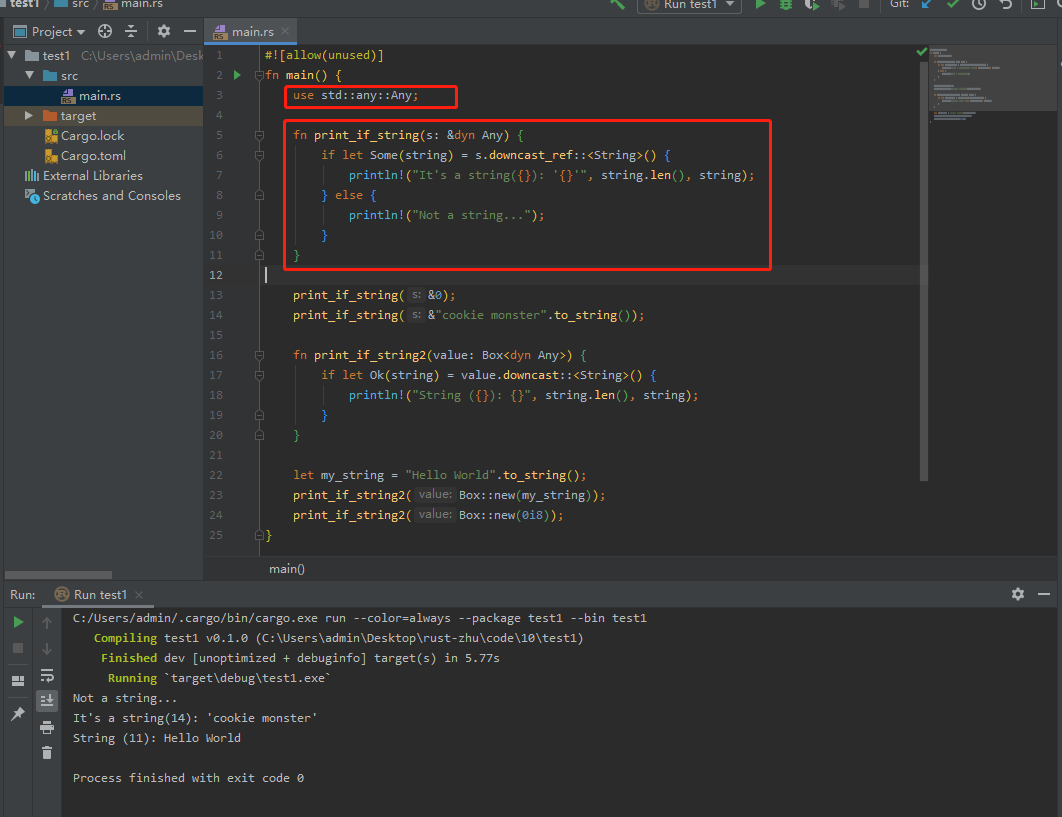
自定义类型使用downcast失败。总有各种各样的错误。采取了直接实现any以及实现any的子类,皆失败。
使用Trait Bound有条件的实现方法
为实现指定特征的结构,提供特定方法。
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}
第一个impl块,返回一个新实例的函数Pair<T>。 但是在下一个impl块中,仅当其内部类型实现了 Display 和 PartialOrd 特征时,Pair<T>才可使用此方法。
在动态类型语言中,如果我们在没有定义方法的类型上调用方法,我们会在运行时遇到错误。但是 Rust 将这些错误移至编译时
生命周期是我们已经使用过的另一种通用类型。生命周期不是确保一个类型具有我们想要的行为,而是确保引用在我们需要时有效。每个引用都有生命周期,这是该引用的有效范围。
大多数时候,生命周期是隐式的和推断的,就像大多数时候,类型是推断的一样。只有在可能存在多种类型时,我们才必须注释类型。以类似的方式,当引用的生命周期可以通过几种不同的方式相关时,我们必须注释生命周期。Rust 要求我们使用通用生命周期参数来注释关系,以确保在运行时使用的实际引用绝对有效。
使用生命周期防止悬挂引用
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {}", r);
}
x在内部范围外失效,在尝试使用被引用的x时,已超出了范围。故而无法编译。
借用检查器
Rust 编译器有一个借用检查器,它比较范围以确定所有借用是否有效。
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {}", r); // |
} // ---------+
这里,我们用'a注释了r的生命周期,用'b注释了x的生命周期。在编译时,Rust比较两个生存期的大小,并看到r的生存期为'a,但它引用的内存的生存期为'b。程序被拒绝,因为'b比'a短:引用对象的生存期没有引用的生存期长。
fn main() {
let x = 5; // ----------+-- 'b
// |
let r = &x; // --+-- 'a |
// | |
println!("r: {}", r); // | |
// --+ |
} // ----------+
这里,x的生命周期为'b,在这种情况下大于'a。这意味着r可以引用x,因为Rust知道r中的引用总是有效的,而x是有效的。
函数中的通用生命周期
只有当一个函数的参数同时满足以下两个条件时,才需要使用生命周期注解:
-
参数是一个引用类型,即 &T 或 &mut T。
-
参数在函数体内被使用,且函数返回一个引用类型,即 &T 或 &mut T。
在这种情况下,编译器需要知道引用的生命周期,以便确保函数返回的引用不会超出参数引用的生命周期。如果参数是在堆上分配的,而不是引用类型,则无需使用生命周期注解。例如,Box<T> 类型的参数就不需要使用生命周期注解。
函数将接受两个字符串切片,并返回一个(较长)字符串切片。
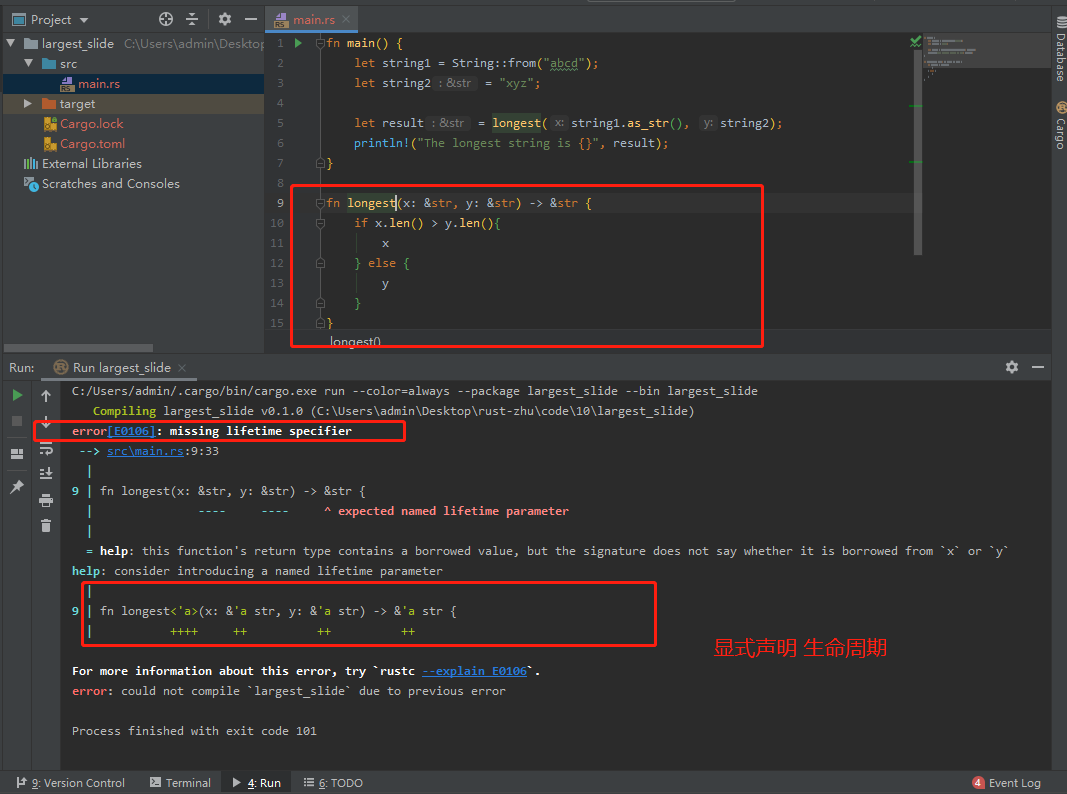
错误原因:因为Rust无法判断所返回的引用是指向x还是y。且当参数传递值有误时,if-else不会执行,故而不能确定返回的引用是否总有效。
生命周期注释语法
生命周期不会改变任何引用的生命期。它们描述了多个引用彼此之前生存期的关系。函数可以接受任何生命期的引用,通过指定泛型生命期参数。
生命周期注释的语法有点不同寻常:生命周期参数的名称必须以撇号(')开头,通常都是小写的,而且非常短,就像泛型类型一样。大多数人使用名称'a '作为第一个生命周期注释。我们将生命周期参数注释放在引用的&之后,使用一个空格将注释与引用的类型分开。
&i32 // a reference
&'a i32 // a reference with an explicit lifetime
&'a mut i32 // a mutable reference with an explicit lifetime
一个生命周期注释本身没有什么意义,这些注释是为了告诉Rust多个引用的通用生命周期参数如何相互关联。
函数签名中的生命周期注释
要在函数签名中使用生命期注释,需要在函数名和参数列表之间的尖括号内声明泛型生命期参数。
该签名表达以下约束:只要两个参数都有效,返回的引用就有效。这是参数的生存期和返回值之间的关系。我们将生命周期命名为'a,然后将它添加到每个引用中,
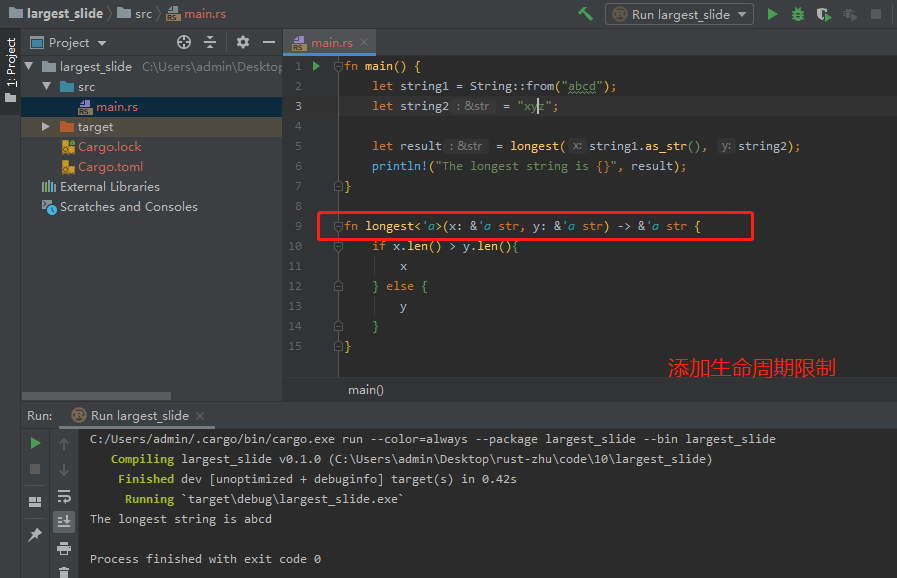
函数签名现在告诉Rust,对于某个生命期'a,函数接受两个形参,这两个形参都是至少与生命期'a一样长的字符串切片。函数签名还告诉Rust,从函数返回的字符串切片将至少与生命期'a一样长。在实践中,这意味着最长函数返回的引用的生命期与函数参数引用的值的生命期中较小的那个相同。这些关系就是我们在分析代码时希望Rust使用的关系。
在函数中注释生命周期时,注释放在函数签名中,而不是函数体中。生命周期注释成为函数契约的一部分,就像签名中的类型一样。让函数签名包含生命周期契约意味着Rust编译器所做的分析可以更简单。
当我们将具体引用传递给longest时,被替换为'a的具体生命期是x的作用域中与y的作用域重叠的部分。换句话说,泛型生命期'a将获得等于x和y的生命期中较小的那部分的具体生命期。
一种情况:
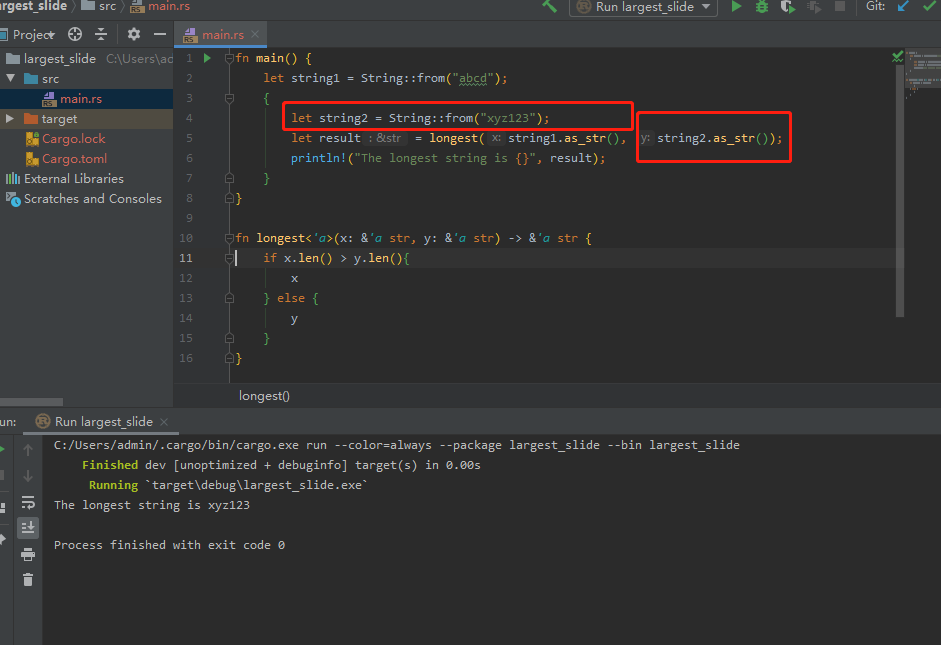
在本例中,string1在外部作用域结束之前都有效,string2在内部作用域结束之前都有效,result引用的值在内部作用域结束之前都有效。故可以运行。
另一种情况:此代码会返回string1的引用,同时string1还未超出作用域,按理来说可以打印。但是rust只认生存期中较小的。故而报错。
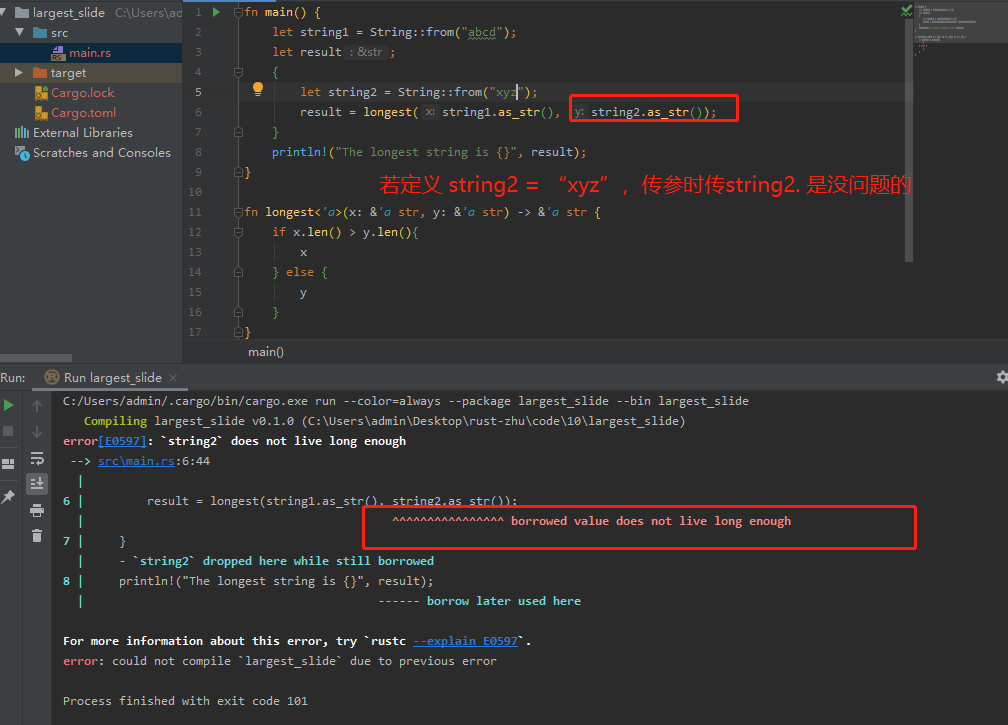
Thinking in Terms of Lifetimes
指定生命周期参数的方式取决于函数正在执行的操作。eg:若只返回第一个形参,而不是最长的,就不需要在y上指定生存期。
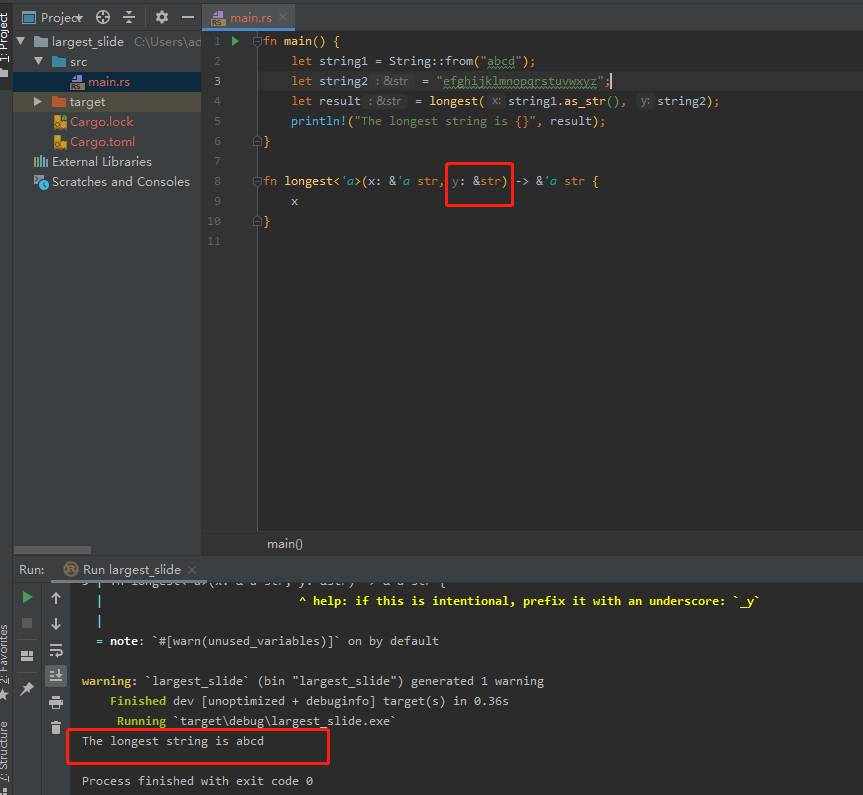
当指定返回类型生命周期,但参数与该生命周期无关时:

修改方法:
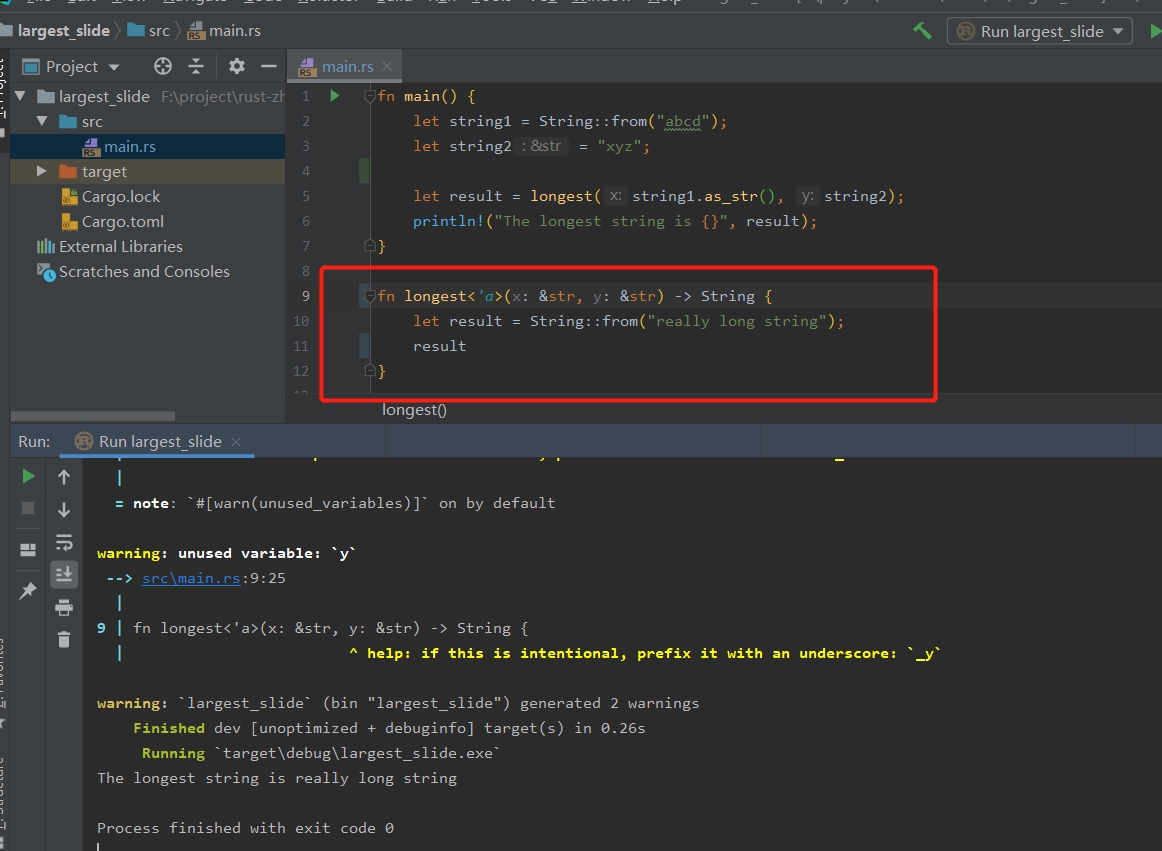
Lifetime Annotations in Struct Definitions
以下情况需要在结构定义中的每个引用上添加一个生命周期注释。
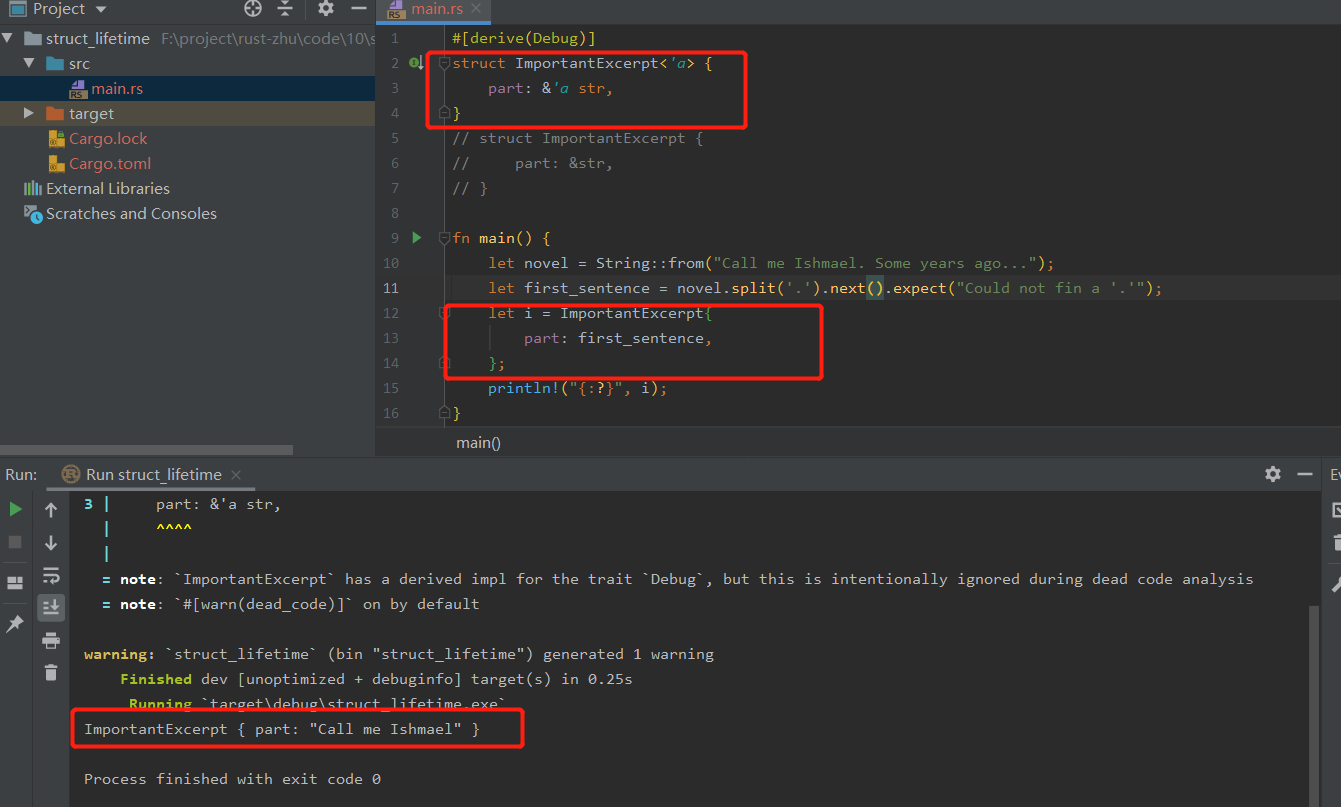
生命周期注解意味着 ImportantExcerpt 的实例不能超出它在 part和part2 字段中所持有的引用的生命周期。
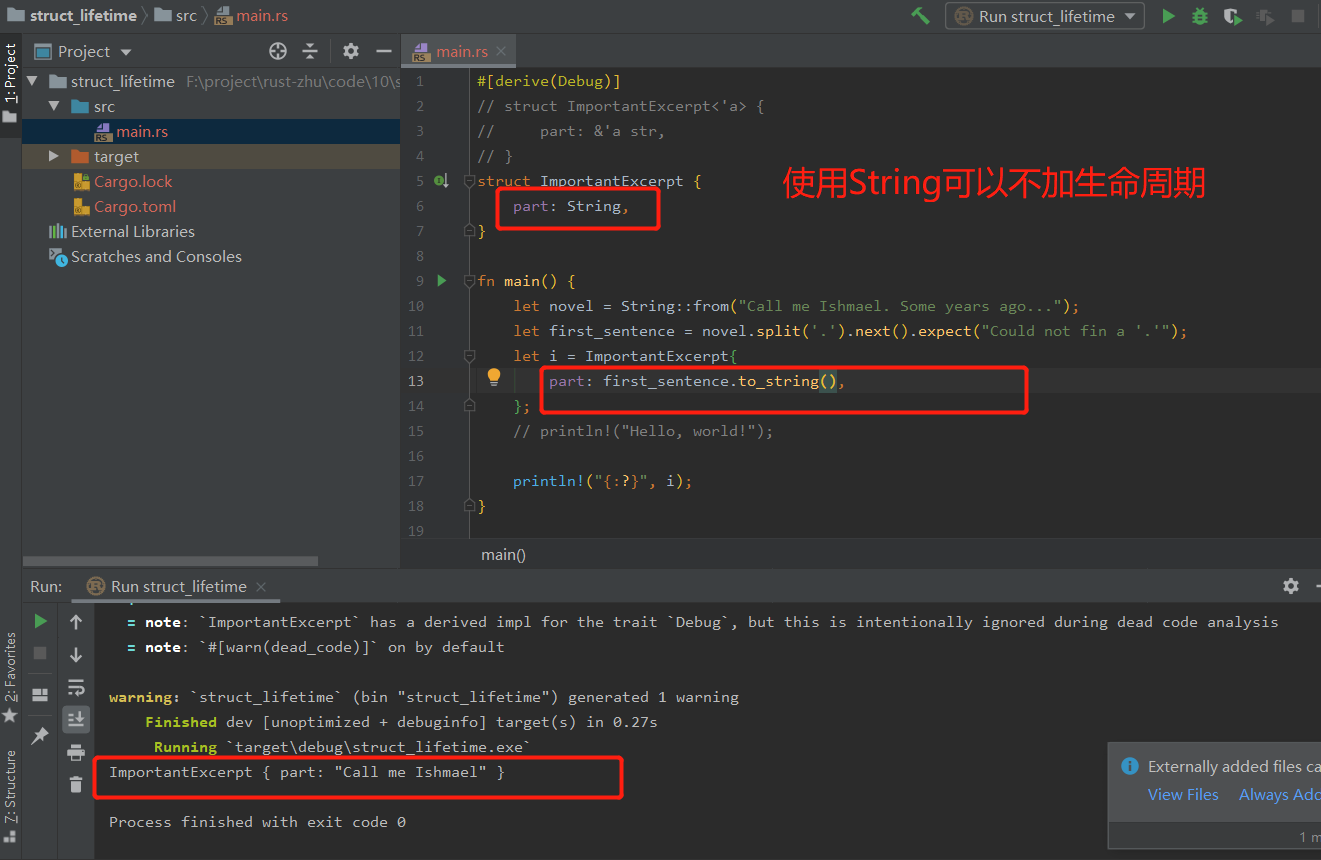
使用String时:
Lifetime Elision
每个引用都有生命周期。需为引用的函数或结构指定生命周期参数。但是也有一些函数会有特殊情况。下面函数编译时没有生命周期。(参数和返回类型是引用)
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
在Rust早期(pre-1.0)此代码不会被编译,因为每个引用都需要一个明确的生命周期。故而签名应写成这样:
fn first_word<'a>(s: &'a str) -> &'a str {
但是随着发展,rust引用分析中添加了 生命周期省略规则。 这是编译器会考虑的一组特定情况,如果代码符合此情况,则无需显式编写生命周期。
函数或方法参数的生命周期称为输入生命周期,返回值的生命周期称为输出生命周期。
当没有显式注释时,编译器使用三个规则来确定引用的生命周期。第一个规则适用于输入生命周期,第二条和第三条规则适用于输出生命周期。如果编译器到达三个规则的末尾仍然有它无法确定生命周期的引用,编译器将停止并报错。规则适用于fn定义和impl块。
规则1:编译器为每个引用参数分配一个生命周期参数。具体来讲,具有一个参数的函数获得一个生命周期参数: fn foo<'a>(x: &'a i32); 有两个参数的函数有两个独立的生命周期参数:fn foo<'a, 'b>(x: &'a i32, y: &'b i32)。以此类推。
规则2:如果只有一个输入生命周期参数,则该生命周期将分配给所有输出生命周期参数:fn foo<'a>(x: &'a i32) -> &'a i32。
规则3(仅使用方法签名):如果有多个输入生命周期参数,但其中一个是 &self 或 &mut self,因为这是一个方法,self 的生命周期将分配给所有输出生命周期参数。这第三条规则使得方法更易于阅读和编写,因为需要的符号更少。
举个例子:
// 我们定义的
fn first_word(s: &str) -> &str {
// 第一条规则适用:经过第一条规则后
fn first_word<'a>(s: &'a str) -> &str {
// 第二条规则适用:经过第二条规则后
fn first_word<'a>(s: &'a str) -> &'a str {
// 满足编译器要求,每个引用都有生命周期
// 另外定义
fn longest(x: &str, y: &str) -> &str {
// 第一条规则适用:经过第一条规则后
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {
// 第二条规则不适应,第三条也不适用
// 返回值无生命周期,无法编译。
Lifetime Annotations in Method Definitions
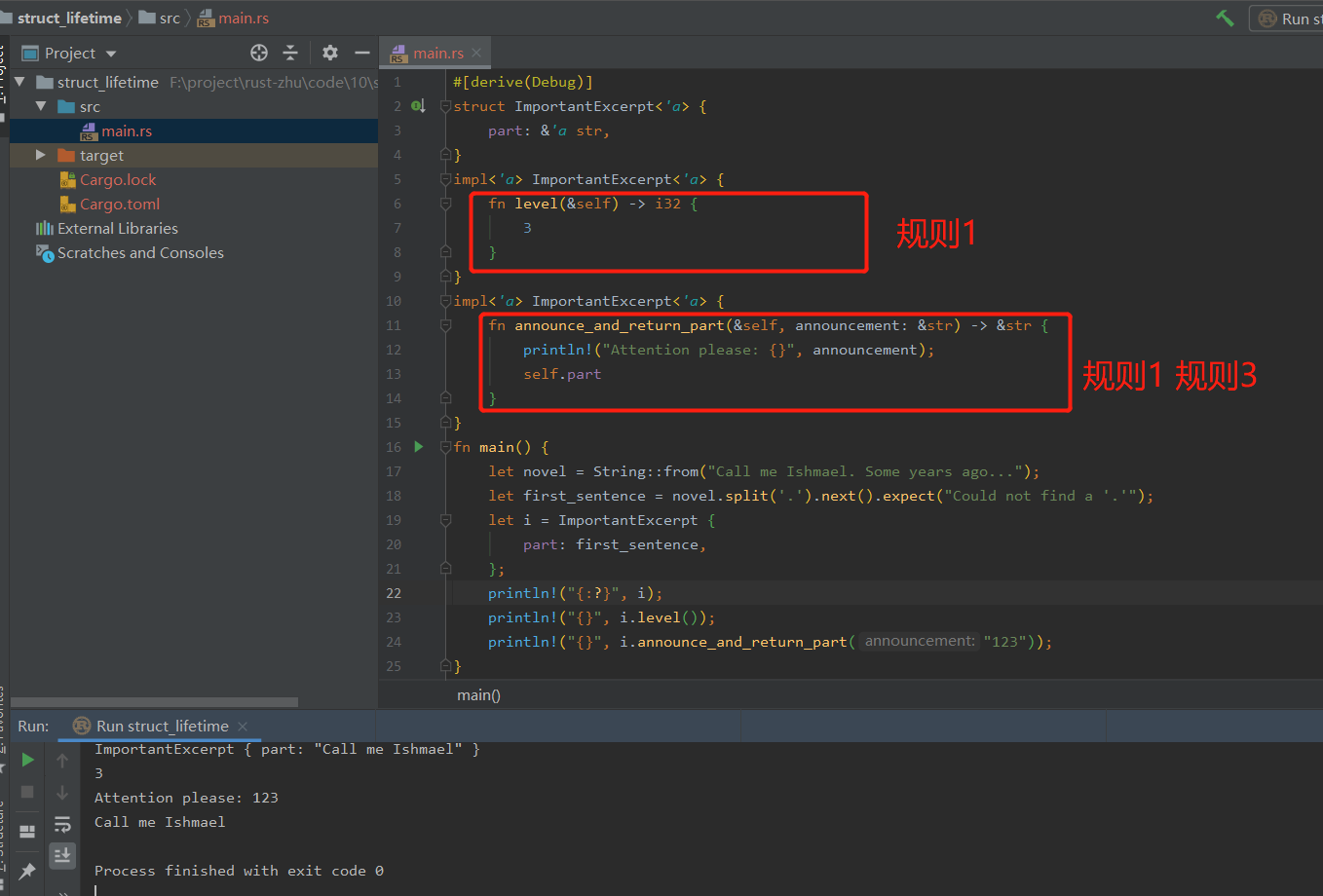
根据生命周期省略规则的第一条规则,Rust 会为 &self 和 announcement 分别分配各自的生命周期。然后,由于其中一个参数是 &self,所以返回类型的生命周期就等同于 &self 的生命周期。
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part(&self, announcement: &str) -> &str {
println!("Attention please: {}", announcement);
self.part
}
}
The Static Lifetime
特殊的生命周期static,表示受影响的引用可以在程序的整个生命周期内存在。所有的字符串字面值都有 static 生命周期。因此它始终可用。因此,所有字符串字面值的生命周期都是 static。
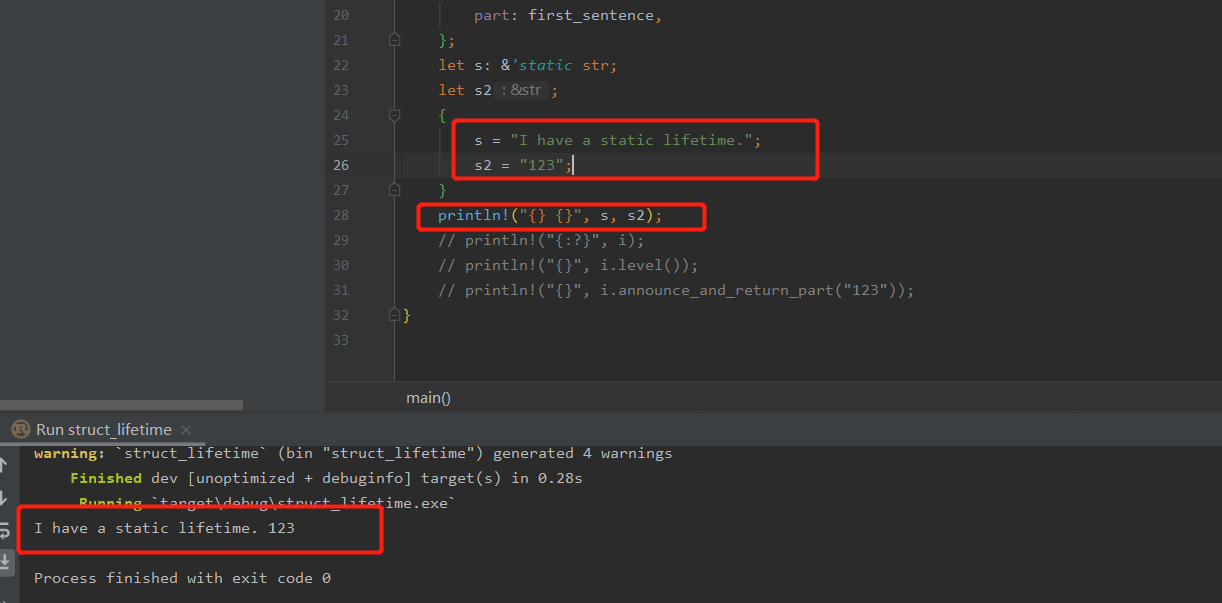
不要使用static来解决悬挂引用或生命周期不匹配问题。应修复问题,而不是直接把生命周期设为整个程序/
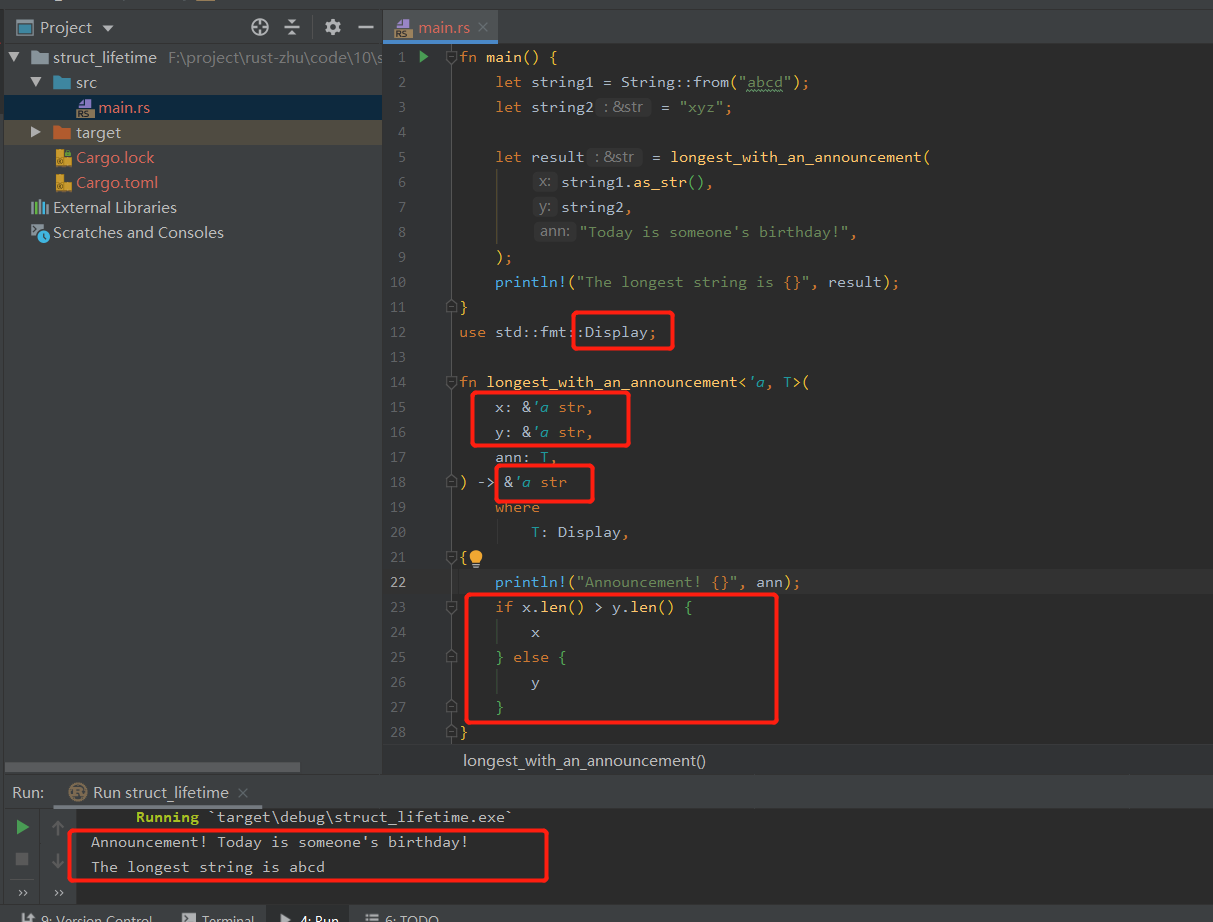
Generic Type Parameters, Trait Bounds, and Lifetimes Together
示例代码:

文章评论
你好啊
@nowhere
Hello!
Good cheer to all on this beautiful day!!!!!
Good luck :)
@XRMip :)