创建一个项目(minigrep),接受两个命令行参数:文件路径和要搜索的字符串。

读取参数值
需要std::env::args来读取命令行参数的值。此函数返回一个命令行参数的迭代器给minigrep。
迭代器:1.迭代器生成一系列值。2.我们可以调用迭代器上的collect方法将其转换为包含迭代器生成的所有元素的集合,例如vector。

在需要的函数嵌套在多个模块中的情况下,选择将父模块而不是函数引入作用域。这样可以使用std::env中的其他函数。这也比添加use std::env::args 然后只使用args调用函数要少一些歧义。
调用 dbg! 宏会将信息输出到标准错误控制台流 (stderr),而 println! 则会输出到标准输出控制台流 (stdout)
注意 std::env::args 在其参数包含无效 Unicode 字符时会 panic。如果你需要接受包含无效 Unicode 字符的参数,需使用 std::env::args_os 代替。这个函数返回 OsString 迭代器而不是 String 迭代器。这里出于简单考虑使用了 std::env::args,因为 OsString 值每个平台都不一样而且比 String 值处理起来更为复杂。
保存参数值到变量

collect函数来创建多种类型的集合,因此我们显式声明了args的类型,以指定我们想要一个字符串向量。虽然在Rust中我们很少需要显式声明类型,但collect是一个经常需要显式声明的函数,因为Rust不能推断出想要的集合类型。
读取文件

重构以改进模块化和错误处理
-
首先将main程序中的多个任务解析成单独函数,模块化。
-
将配置变量存到一个结构中,以明确用途。再此代码中即app_name,query,file_path。防止后期变量变多后,理解困难。
-
expect总是打印相同的错误信息,没有提供有用信息。
-
最好将所有的错误处理代码都在一个地方,便于后期维护。
二进制项目的模块化
将多个任务的责任分配给主要功能的组织问题在许多二进制项目中都很常见。因此,Rust社区已经制定了指南,以在main函数开始变得庞大时分离二进制程序的不同关注点。这个过程包括以下步骤:
-
将项目拆分成main.rs和lib.rs,将逻辑部分移至lib.rs。
-
只把简单的命令行解析逻辑留在main.rs文件中。
-
当命令行解析逻辑开始变得复杂时,将其从main.rs文件中提取出来,并将其移动到lib.rs文件中。
拆分后再main函数中保留的职责应在以下几个方面:
-
使用参数值调用命令行解析逻辑
-
设置任何其他配置
-
调用lib.rs中的run函数
-
处理运行函数时可能产生的错误
这种模式是关注点分离:main.rs文件负责运行程序,而lib.rs文件则处理手头任务的所有逻辑。由于你无法直接测试main函数,因此这种结构让你通过将逻辑移动到lib.rs文件中的函数中来测试程序的所有逻辑。留在main.rs文件中的代码将足够小,以便通过阅读它来验证其正确性。
提取参数函数
将提取命令行解析的逻辑封装到一个函数中,将此逻辑移至src/lib.rs中。(目前函数暂时放在src.main.rs)


不再通过下标在主函数取变量,将整个向量传递给parse_config函数。parse_config决定哪个参数应该放在哪个变量中,并将值传递回main。在main中创建查询变量和file_path变量,但是main不再负责决定命令行参数和变量如何对应。
分组配置值
目前使用parse_config函数获取一个元组。如果变量名不明确,在main中对应会很困难,其次没有将这两个相关的配置值关联起来。现将返回值修改为结构体。

添加结构体Config用来存取query和file_path。将parse_config的返回值设为Config。parse_config函数体中,因为返回值不再是&str,结构体字段为String故需要取到String的所有权。但main中的args变量是参数值的所有者,只允许parse_config函数借用它们,这意味着如果Config试图获得args中的值的所有权,我们就违反了Rust的借用规则。
可通过对值调用clone方法来为Config实例提供数据的完整副本,这比存储对字符串数据的引用需要更多的时间和内存(增加运行成本),好处是克隆数据不需要管理引用的生存期。
为Config创建构造函数
将创建Config的逻辑从parse_config函数移至Config结构体的构造函数中。[Struct_name]::new是更惯用的创建结构体实例的办法。

修改错误处理
此程序当运行时传递的配置小于2个时,将会返回错误信息"index of bounds"。而这对用户理解错误没什么实质帮助。
改进错误提示
在new函数中检查切片长度,当会产生下标越界时,panic会结束程序并提示"not enough arguments"错误。

现在当输入参数不足时,会返回给用户一个更合理的错误信息。但panic更适合处理编程问题,而非返回错误提示。当预期失败时,返回Result比panic!更合适。
返回result代替panic!
首先将函数名改为build,因为new函数不应失败。build函数在成功情况下返回一个Config实例,在失败时返回一个&'静态str。我们的错误值将始终是具有“静态生命期”的字符串字面量。

函数体不再调用panic!当用户没有传递足够的参数时,返回一个Err值,并将Config返回值包装在一个Ok中。
使用config::build处理错误
exit(1)函数,以非零退出状态是一种约定表示程序以错误状态退出。

错误情况下运行的闭包中的代码只有两行:打印err值,然后使用process::exit函数停止程序并返回作为退出状态代码传递的数字。这类似于panic!但是不再得到所有额外的输出。
unwrap_or_else()方法接受一个回调函数作为参数,如果Result的值是Ok,则返回其内部的值,如果Result的值是Err,则调用传递给unwrap_or_else的回调函数,并返回其返回值。回调函数允许对错误情况进行自定义处理。
从main中提取逻辑
将程序中不涉及配置和处理错误的逻辑,封装到run函数中。

修改run的错误处理

Box<dyn Error>意味着函数将返回一个实现Error特征的类型,但我们不必指定返回值是什么特定类型。这使我们能够灵活地返回在不同错误情况下可能具有不同类型的错误值。该dyn关键字是“动态”的缩写。
在main函数中处理返回的错误
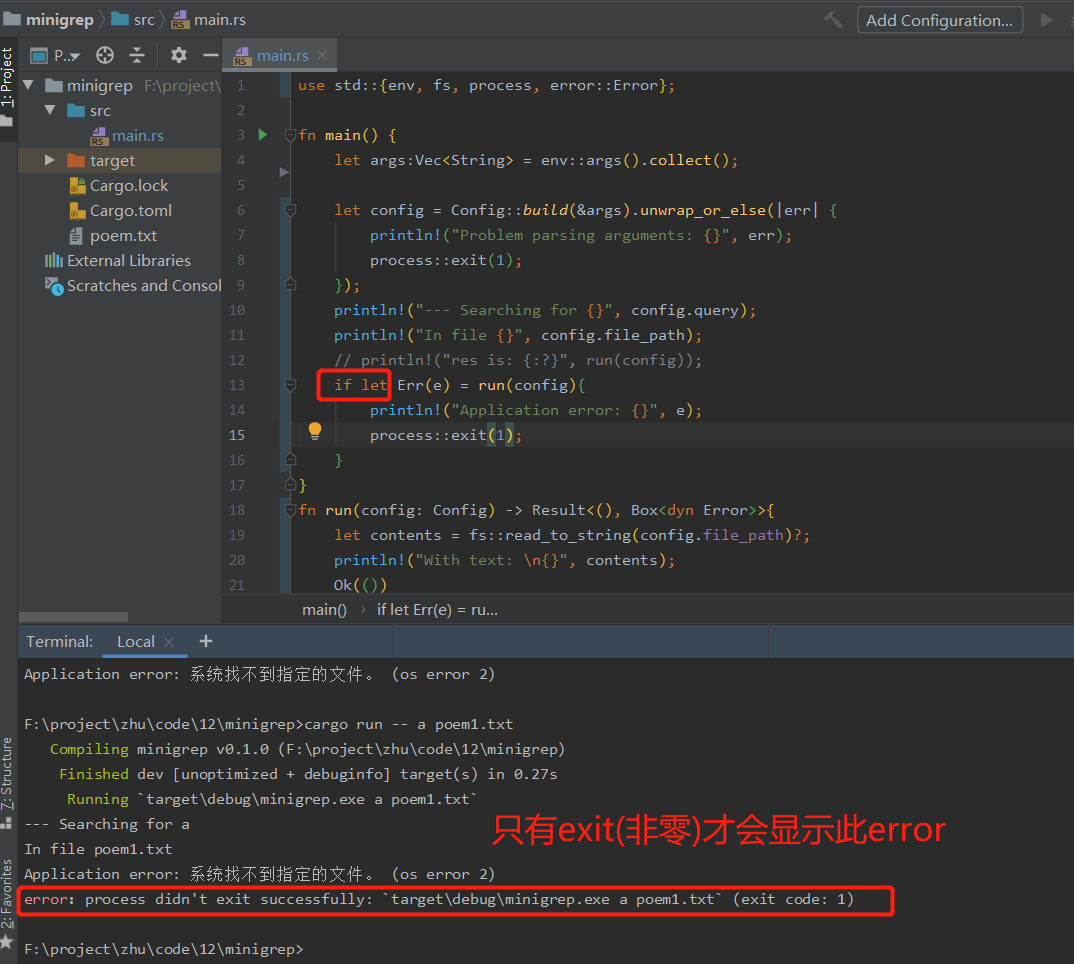
使用if let来检查run返回的Err值,因为run()在成功的情况下,我们只关心检测错误,所以我们不需要unwrap_or_else来返回未包装的值,它只会是()。

将代码拆分到Library Crate
将所有不是main函数的代码从src/main.rs移动到 src/lib.rs:
-
函数
run定义 -
相关
use声明 -
Config的定义 -
Config::build函数定义

将lib.rs里的struct、fields、method和function都设为pub,通过pub关键字设为公共API。
使用测试驱动开发(TDD)的过程来开发库的功能
使用测试驱动开发(TDD)的过程将搜索逻辑添加到minigrep程序中,具体步骤如下:
-
编写一个失败的测试并运行它,以确保它以你期望的方式失败。
-
编写或修改足够的代码以使新测试通过。
-
重构你刚添加或修改的代码,并确保测试继续通过。
-
重复从步骤1开始!
编写一个失败的测试
在src/lib.rs中添加一个tests模块和一个test函数,就像在第11章中所做的那样。test函数指定了我们希望search函数具有的行为:它将获取一个查询和要搜索的文本,并仅返回包含查询的文本行。

我们需要在search的签名中定义显式生命周期'a,并将该生命周期与contents参数和返回值一起使用。生命周期参数指定哪个参数生命周期与返回值的生命周期相关联。在这种情况下,我们表明返回的向量应该包含引用参数contents的片段的字符串切片(而不是参数query的切片)。
换句话说,我们告诉Rust,search函数返回的数据将与在contents参数中传递给search函数的数据一样长寿。切片引用的数据需要对引用有效;如果编译器假定我们正在使用query而不是contents的字符串切片,它将无法正确进行安全检查。
编写代码以通过测试
目前,我们的测试失败,因为我们总是返回一个空向量。为了修复它并实现search,我们的程序需要按照以下步骤进行:
-
遍历contents的每一行。
-
检查该行是否包含我们的查询字符串。 如果包含,则将其添加到我们正在返回的值列表中。 如果不包含,则什么都不做。
-
返回匹配的结果列表。
使用lines方法遍历每行
Rust有一个有用的方法来处理字符串逐行迭代,方便地命名为lines。lines方法返回一个迭代器。
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines(){
// do something with line
}
}
#####
遍历每行查找query并处理结果
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines(){
if line.contains(query){
results.push(line);
}
}
results
}
测试结果:

在run() 中使用 search()
pub fn run(config: Config) -> Result<(), Box<dyn Error>>{
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents){
println!("{}", line);
}
// println!("With text: \n{}", contents);
Ok(())
}
运行结果:

使用环境变量
通过环境变量来打开不区分大小写的搜索选项。
为不区分大小写搜索函数编写一个失败的测试
继续遵循TDD过程,首先编写一个失败的测试。添加一个search_case_insensitive(),当环境变量有值时将调用该函数。

分别在测试里新增内容,检测就内容是否会无视大小写,以及新内容能否通过大小写匹配。
实现search_case_insensitive()
search_case_insensitive()与search函数唯一不同的地方,在于函数体内将query和line小写。下图为添加后的测试结果:

为结构体添加字段来选择是否切换大小写
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool, // 用于判断是否检测大小写
}
在run()中,通过字段选择调用的函数

添加环境变量代码,处理环境变量的函数在标准库中的env模块(std::env)中,故将模块置于src/lib.rs的顶部。
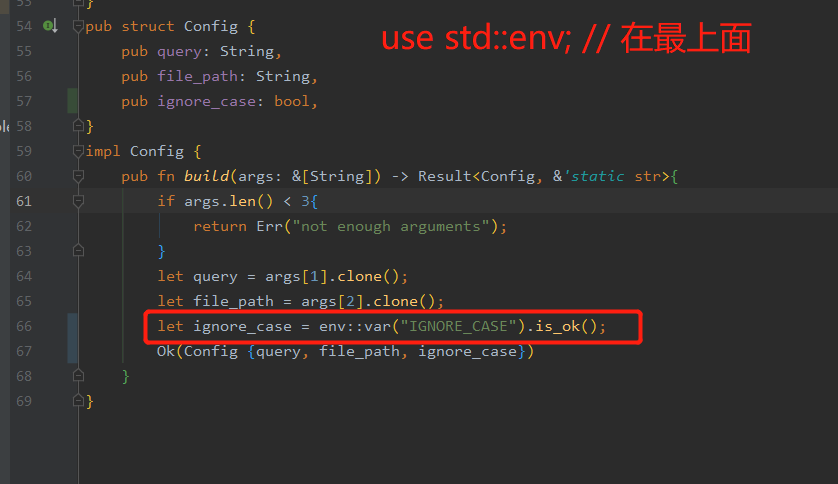
env:var() 接收一个环境变量名称,如果此环境变量未设置将会返回VarError,如果环境变量名称包含等于字符(=)或NUL字符,则此函数可能返回VarError,如果环境变量不是有效的Unicode字符,此函数将返回VarError。
is_ok() Returns true if the result is .
pub enum VarError {
NotPresent,
NotUnicode(OsString),
}
Powershell下的运行图:

移除环境变量:

搜索环境变量的顺序:
-
当前进程的环境变量。
-
用户环境变量。
-
系统环境变量。
使用stderr代替stdout处理错误信息
在大多数终端中,有两种输出类型:标准输出(stdout)用于一般信息,标准错误(stderr)用于错误消息。这种区别使用户能够选择将程序的成功输出定向到文件,但仍将错误消息打印到屏幕上。println!宏只能打印到标准输出。
检查错误信息写入的位置
在代码中引发一个错误,查看内容显示的位置。为了演示这种行为,我们将使用>和我们想要将标准输出流重定向到的文件路径,即output.txt。我们不会传递任何参数,这应该会导致一个错误:

程序目前将错误信息也写入了文件,文件中应只存在运行成功的数据,故需进行更改。
使用stderr打印错误
标准库提供eprintln!宏,打印到标准错误流(stderr)。
错误情况:

正确情况:

一些额外知识:


文章评论